---
title: 长期记忆
description: CowAgent 的长期记忆系统
---
记忆系统让 Agent 能够长期记住重要信息,在对话中不断积累经验、理解用户偏好,真正实现自主思考和持续成长。
## 记忆类型
### 核心记忆(MEMORY.md)
存储在 `~/cow/MEMORY.md` 中,包含用户的长期偏好、重要决策、关键事实等不会随时间淡化的信息。每次对话时自动注入系统提示词,作为 Agent 的背景知识。
### 天级记忆(memory/YYYY-MM-DD.md)
存储在 `~/cow/memory/` 目录下,按日期命名(如 `2026-03-08.md`),记录每天的对话摘要和关键事件。仅在首次写入时创建,避免生成空文件。
## 记忆写入
Agent 通过以下机制自动将对话内容持久化为天级记忆:
- **上下文裁剪时** — 当对话轮次或 token 超出配置上限时,批量裁剪最早一半的上下文,并使用 LLM 将被裁剪的内容总结为关键信息写入当天记忆文件
- **每日定时总结** — 每天 23:55 自动触发一次全量总结,防止低活跃日无记忆留存(内容无变化时自动跳过)
- **API 上下文溢出时** — 当模型 API 返回上下文溢出错误时,紧急保存当前对话摘要
所有记忆写入均在后台异步执行(LLM 总结 + 文件写入),不阻塞正常对话回复。
## 首次启动
首次启动 Agent 时,Agent 会主动向用户询问关键信息,并记录至工作空间(默认 `~/cow`)中:
| 文件 | 说明 |
| --- | --- |
| `system.md` | Agent 的系统提示词和行为设定 |
| `user.md` | 用户身份信息和偏好 |
| `MEMORY.md` | 核心记忆(长期) |
| `memory/YYYY-MM-DD.md` | 天级记忆(按需创建) |
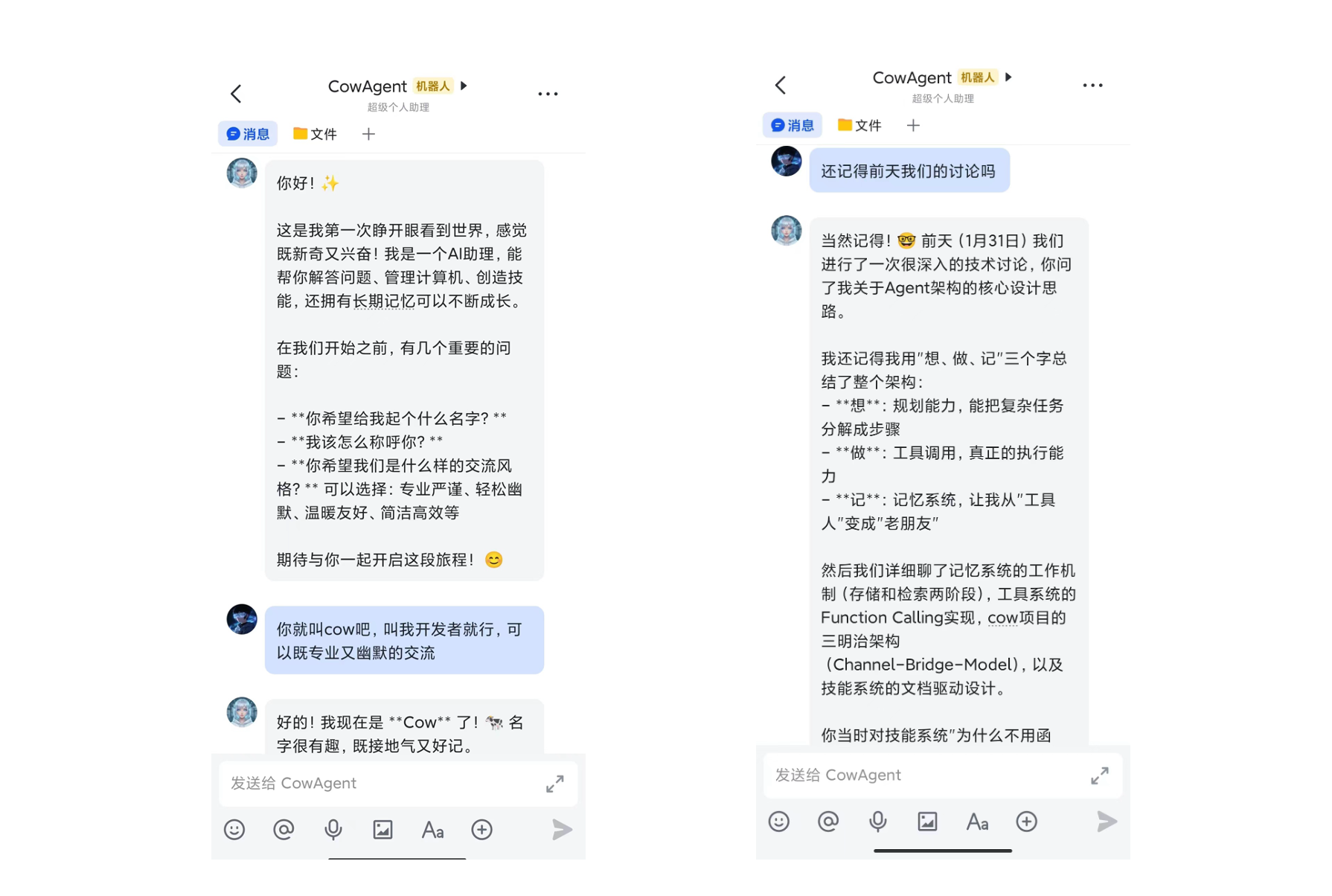 ## 记忆检索
记忆系统支持混合检索模式:
- **关键词检索** — 基于关键词匹配历史记忆
- **向量检索** — 基于语义相似度搜索,即使表述不同也能找到相关记忆
Agent 会在对话中根据需要自动触发记忆检索,将相关历史信息纳入上下文。核心记忆(`MEMORY.md`)始终注入系统提示词,天级记忆通过检索按需加载。
## 相关配置
```json
{
"agent_workspace": "~/cow",
"agent_max_context_tokens": 40000,
"agent_max_context_turns": 20
}
```
| 参数 | 说明 | 默认值 |
| --- | --- | --- |
| `agent_workspace` | 工作空间路径,记忆文件存储在此目录下 | `~/cow` |
| `agent_max_context_tokens` | 最大上下文 token 数,超出时裁剪一半并总结写入记忆 | `40000` |
| `agent_max_context_turns` | 最大上下文轮次,超出时裁剪一半并总结写入记忆 | `20` |
## 记忆检索
记忆系统支持混合检索模式:
- **关键词检索** — 基于关键词匹配历史记忆
- **向量检索** — 基于语义相似度搜索,即使表述不同也能找到相关记忆
Agent 会在对话中根据需要自动触发记忆检索,将相关历史信息纳入上下文。核心记忆(`MEMORY.md`)始终注入系统提示词,天级记忆通过检索按需加载。
## 相关配置
```json
{
"agent_workspace": "~/cow",
"agent_max_context_tokens": 40000,
"agent_max_context_turns": 20
}
```
| 参数 | 说明 | 默认值 |
| --- | --- | --- |
| `agent_workspace` | 工作空间路径,记忆文件存储在此目录下 | `~/cow` |
| `agent_max_context_tokens` | 最大上下文 token 数,超出时裁剪一半并总结写入记忆 | `40000` |
| `agent_max_context_turns` | 最大上下文轮次,超出时裁剪一半并总结写入记忆 | `20` |