mirror of
https://github.com/zhayujie/chatgpt-on-wechat.git
synced 2026-03-18 12:40:06 +08:00
Merge remote-tracking branch 'upstream/master'
This commit is contained in:
@@ -111,7 +111,7 @@ class ChatService:
|
||||
logger.info(f"[ChatService] Starting agent run: session={session_id}, query={query[:80]}")
|
||||
|
||||
from config import conf
|
||||
max_context_turns = conf().get("agent_max_context_turns", 30)
|
||||
max_context_turns = conf().get("agent_max_context_turns", 20)
|
||||
|
||||
# Get full system prompt with skills
|
||||
full_system_prompt = agent.get_full_system_prompt()
|
||||
|
||||
@@ -480,7 +480,7 @@ class Agent:
|
||||
|
||||
# Get max_context_turns from config
|
||||
from config import conf
|
||||
max_context_turns = conf().get("agent_max_context_turns", 30)
|
||||
max_context_turns = conf().get("agent_max_context_turns", 20)
|
||||
|
||||
# Create stream executor with copied message history
|
||||
executor = AgentStreamExecutor(
|
||||
|
||||
@@ -636,11 +636,16 @@ class AgentStreamExecutor:
|
||||
])
|
||||
|
||||
# Check if error is message format error (incomplete tool_use/tool_result pairs)
|
||||
# This happens when previous conversation had tool failures
|
||||
# This happens when previous conversation had tool failures or context trimming
|
||||
# broke tool_use/tool_result pairs.
|
||||
is_message_format_error = any(keyword in error_str_lower for keyword in [
|
||||
'tool_use', 'tool_result', 'without', 'immediately after',
|
||||
'corresponding', 'must have', 'each'
|
||||
]) and 'status: 400' in error_str_lower
|
||||
'corresponding', 'must have', 'each',
|
||||
'tool_call_id', 'is not found', 'tool_calls',
|
||||
'must be a response to a preceeding message'
|
||||
]) and ('400' in error_str_lower or 'status: 400' in error_str_lower
|
||||
or 'invalid_request' in error_str_lower
|
||||
or 'invalidparameter' in error_str_lower)
|
||||
|
||||
if is_context_overflow or is_message_format_error:
|
||||
error_type = "context overflow" if is_context_overflow else "message format error"
|
||||
@@ -659,9 +664,10 @@ class AgentStreamExecutor:
|
||||
)
|
||||
|
||||
# Aggressive trim didn't help or this is a message format error
|
||||
# -> clear everything
|
||||
# -> clear everything and also purge DB to prevent reload of dirty data
|
||||
logger.warning("🔄 Clearing conversation history to recover")
|
||||
self.messages.clear()
|
||||
self._clear_session_db()
|
||||
if is_context_overflow:
|
||||
raise Exception(
|
||||
"抱歉,对话历史过长导致上下文溢出。我已清空历史记录,请重新描述你的需求。"
|
||||
@@ -906,24 +912,55 @@ class AgentStreamExecutor:
|
||||
|
||||
def _validate_and_fix_messages(self):
|
||||
"""
|
||||
Validate message history and fix incomplete tool_use/tool_result pairs.
|
||||
Claude API requires each tool_use to have a corresponding tool_result immediately after.
|
||||
Validate message history and fix broken tool_use/tool_result pairs.
|
||||
|
||||
Historical messages restored from DB are text-only (no tool calls),
|
||||
so this method only needs to handle edge cases in the current session:
|
||||
- Trailing assistant message with tool_use but no following tool_result
|
||||
(e.g. process was interrupted mid-execution)
|
||||
- Orphaned tool_result at the start of messages (e.g. after context
|
||||
trimming removed the preceding assistant tool_use)
|
||||
"""
|
||||
if not self.messages:
|
||||
return
|
||||
|
||||
# Check last message for incomplete tool_use
|
||||
if len(self.messages) > 0:
|
||||
|
||||
removed = 0
|
||||
|
||||
# Remove trailing incomplete tool_use assistant messages
|
||||
while self.messages:
|
||||
last_msg = self.messages[-1]
|
||||
if last_msg.get("role") == "assistant":
|
||||
# Check if assistant message has tool_use blocks
|
||||
content = last_msg.get("content", [])
|
||||
if isinstance(content, list):
|
||||
has_tool_use = any(block.get("type") == "tool_use" for block in content)
|
||||
if has_tool_use:
|
||||
# This is incomplete - remove it
|
||||
logger.warning(f"⚠️ Removing incomplete tool_use message from history")
|
||||
self.messages.pop()
|
||||
if isinstance(content, list) and any(
|
||||
isinstance(b, dict) and b.get("type") == "tool_use"
|
||||
for b in content
|
||||
):
|
||||
logger.warning("⚠️ Removing trailing incomplete tool_use assistant message")
|
||||
self.messages.pop()
|
||||
removed += 1
|
||||
continue
|
||||
break
|
||||
|
||||
# Remove leading orphaned tool_result user messages
|
||||
while self.messages:
|
||||
first_msg = self.messages[0]
|
||||
if first_msg.get("role") == "user":
|
||||
content = first_msg.get("content", [])
|
||||
if isinstance(content, list) and any(
|
||||
isinstance(b, dict) and b.get("type") == "tool_result"
|
||||
for b in content
|
||||
) and not any(
|
||||
isinstance(b, dict) and b.get("type") == "text"
|
||||
for b in content
|
||||
):
|
||||
logger.warning("⚠️ Removing leading orphaned tool_result user message")
|
||||
self.messages.pop(0)
|
||||
removed += 1
|
||||
continue
|
||||
break
|
||||
|
||||
if removed > 0:
|
||||
logger.info(f"🔧 Message validation: removed {removed} broken message(s)")
|
||||
|
||||
def _identify_complete_turns(self) -> List[Dict]:
|
||||
"""
|
||||
@@ -946,24 +983,30 @@ class AgentStreamExecutor:
|
||||
content = msg.get('content', [])
|
||||
|
||||
if role == 'user':
|
||||
# 检查是否是用户查询(不是工具结果)
|
||||
# Determine if this is a real user query (not a tool_result injection
|
||||
# or an internal hint message injected by the agent loop).
|
||||
is_user_query = False
|
||||
has_tool_result = False
|
||||
if isinstance(content, list):
|
||||
is_user_query = any(
|
||||
block.get('type') == 'text'
|
||||
for block in content
|
||||
if isinstance(block, dict)
|
||||
has_text = any(
|
||||
isinstance(block, dict) and block.get('type') == 'text'
|
||||
for block in content
|
||||
)
|
||||
has_tool_result = any(
|
||||
isinstance(block, dict) and block.get('type') == 'tool_result'
|
||||
for block in content
|
||||
)
|
||||
# A message with tool_result is always internal, even if it
|
||||
# also contains text blocks (shouldn't happen, but be safe).
|
||||
is_user_query = has_text and not has_tool_result
|
||||
elif isinstance(content, str):
|
||||
is_user_query = True
|
||||
|
||||
if is_user_query:
|
||||
# 开始新轮次
|
||||
if current_turn['messages']:
|
||||
turns.append(current_turn)
|
||||
current_turn = {'messages': [msg]}
|
||||
else:
|
||||
# 工具结果,属于当前轮次
|
||||
current_turn['messages'].append(msg)
|
||||
else:
|
||||
# AI 回复,属于当前轮次
|
||||
@@ -1252,6 +1295,24 @@ class AgentStreamExecutor:
|
||||
f"~{current_tokens + system_tokens} -> ~{accumulated_tokens + system_tokens} tokens)"
|
||||
)
|
||||
|
||||
def _clear_session_db(self):
|
||||
"""
|
||||
Clear the current session's persisted messages from SQLite DB.
|
||||
|
||||
This prevents dirty data (broken tool_use/tool_result pairs) from being
|
||||
reloaded on the next request or after a restart.
|
||||
"""
|
||||
try:
|
||||
session_id = getattr(self.agent, '_current_session_id', None)
|
||||
if not session_id:
|
||||
return
|
||||
from agent.memory import get_conversation_store
|
||||
store = get_conversation_store()
|
||||
store.clear_session(session_id)
|
||||
logger.info(f"🗑️ Cleared dirty session data from DB: {session_id}")
|
||||
except Exception as e:
|
||||
logger.warning(f"Failed to clear session DB: {e}")
|
||||
|
||||
def _prepare_messages(self) -> List[Dict[str, Any]]:
|
||||
"""
|
||||
Prepare messages to send to LLM
|
||||
|
||||
@@ -3,6 +3,7 @@ Bash tool - Execute bash commands
|
||||
"""
|
||||
|
||||
import os
|
||||
import re
|
||||
import sys
|
||||
import subprocess
|
||||
import tempfile
|
||||
@@ -83,12 +84,13 @@ SAFETY:
|
||||
|
||||
# Load environment variables from ~/.cow/.env if it exists
|
||||
env_file = expand_path("~/.cow/.env")
|
||||
dotenv_vars = {}
|
||||
if os.path.exists(env_file):
|
||||
try:
|
||||
from dotenv import dotenv_values
|
||||
env_vars = dotenv_values(env_file)
|
||||
env.update(env_vars)
|
||||
logger.debug(f"[Bash] Loaded {len(env_vars)} variables from {env_file}")
|
||||
dotenv_vars = dotenv_values(env_file)
|
||||
env.update(dotenv_vars)
|
||||
logger.debug(f"[Bash] Loaded {len(dotenv_vars)} variables from {env_file}")
|
||||
except ImportError:
|
||||
logger.debug("[Bash] python-dotenv not installed, skipping .env loading")
|
||||
except Exception as e:
|
||||
@@ -100,6 +102,13 @@ SAFETY:
|
||||
else:
|
||||
logger.debug(f"[Bash] Process User: {os.environ.get('USERNAME', os.environ.get('USER', 'unknown'))}")
|
||||
|
||||
# On Windows, convert $VAR references to %VAR% for cmd.exe
|
||||
if sys.platform == "win32":
|
||||
env["PYTHONIOENCODING"] = "utf-8"
|
||||
command = self._convert_env_vars_for_windows(command, dotenv_vars)
|
||||
if command and not command.strip().lower().startswith("chcp"):
|
||||
command = f"chcp 65001 >nul 2>&1 && {command}"
|
||||
|
||||
# Execute command with inherited environment variables
|
||||
result = subprocess.run(
|
||||
command,
|
||||
@@ -108,6 +117,8 @@ SAFETY:
|
||||
stdout=subprocess.PIPE,
|
||||
stderr=subprocess.PIPE,
|
||||
text=True,
|
||||
encoding="utf-8",
|
||||
errors="replace",
|
||||
timeout=timeout,
|
||||
env=env
|
||||
)
|
||||
@@ -131,6 +142,8 @@ SAFETY:
|
||||
stdout=subprocess.PIPE,
|
||||
stderr=subprocess.PIPE,
|
||||
text=True,
|
||||
encoding="utf-8",
|
||||
errors="replace",
|
||||
timeout=timeout,
|
||||
env=env
|
||||
)
|
||||
@@ -258,3 +271,21 @@ SAFETY:
|
||||
return "This command will recursively delete system directories"
|
||||
|
||||
return "" # No warning needed
|
||||
|
||||
@staticmethod
|
||||
def _convert_env_vars_for_windows(command: str, dotenv_vars: dict) -> str:
|
||||
"""
|
||||
Convert bash-style $VAR / ${VAR} references to cmd.exe %VAR% syntax.
|
||||
Only converts variables loaded from .env (user-configured API keys etc.)
|
||||
to avoid breaking $PATH, jq expressions, regex, etc.
|
||||
"""
|
||||
if not dotenv_vars:
|
||||
return command
|
||||
|
||||
def replace_match(m):
|
||||
var_name = m.group(1) or m.group(2)
|
||||
if var_name in dotenv_vars:
|
||||
return f"%{var_name}%"
|
||||
return m.group(0)
|
||||
|
||||
return re.sub(r'\$\{(\w+)\}|\$(\w+)', replace_match, command)
|
||||
|
||||
@@ -240,8 +240,8 @@ class Read(BaseTool):
|
||||
"message": f"文件过大 ({format_size(file_size)} > 50MB),无法读取内容。文件路径: {absolute_path}"
|
||||
})
|
||||
|
||||
# Read file
|
||||
with open(absolute_path, 'r', encoding='utf-8') as f:
|
||||
# Read file (utf-8-sig strips BOM automatically on Windows)
|
||||
with open(absolute_path, 'r', encoding='utf-8-sig') as f:
|
||||
content = f.read()
|
||||
|
||||
# Truncate content if too long (20K characters max for model context)
|
||||
|
||||
@@ -332,9 +332,10 @@ class AgentBridge:
|
||||
Returns:
|
||||
Reply object
|
||||
"""
|
||||
session_id = None
|
||||
agent = None
|
||||
try:
|
||||
# Extract session_id from context for user isolation
|
||||
session_id = None
|
||||
if context:
|
||||
session_id = context.kwargs.get("session_id") or context.get("session_id")
|
||||
|
||||
@@ -371,6 +372,9 @@ class AgentBridge:
|
||||
if context and hasattr(agent, 'model'):
|
||||
agent.model.channel_type = context.get("channel_type", "")
|
||||
|
||||
# Store session_id on agent so executor can clear DB on fatal errors
|
||||
agent._current_session_id = session_id
|
||||
|
||||
# Record message count before execution so we can diff new messages
|
||||
with agent.messages_lock:
|
||||
pre_run_len = len(agent.messages)
|
||||
@@ -395,7 +399,17 @@ class AgentBridge:
|
||||
channel_type = (context.get("channel_type") or "") if context else ""
|
||||
with agent.messages_lock:
|
||||
new_messages = agent.messages[pre_run_len:]
|
||||
self._persist_messages(session_id, list(new_messages), channel_type)
|
||||
if new_messages:
|
||||
self._persist_messages(session_id, list(new_messages), channel_type)
|
||||
elif pre_run_len > 0 and len(agent.messages) == 0:
|
||||
# Agent cleared its messages (recovery from format error / overflow)
|
||||
# Also clear the DB to prevent reloading dirty data
|
||||
try:
|
||||
from agent.memory import get_conversation_store
|
||||
get_conversation_store().clear_session(session_id)
|
||||
logger.info(f"[AgentBridge] Cleared DB for recovered session: {session_id}")
|
||||
except Exception as e:
|
||||
logger.warning(f"[AgentBridge] Failed to clear DB after recovery: {e}")
|
||||
|
||||
# Check if there are files to send (from read tool)
|
||||
if hasattr(agent, 'stream_executor') and hasattr(agent.stream_executor, 'files_to_send'):
|
||||
@@ -415,6 +429,18 @@ class AgentBridge:
|
||||
|
||||
except Exception as e:
|
||||
logger.error(f"Agent reply error: {e}")
|
||||
# If the agent cleared its messages due to format error / overflow,
|
||||
# also purge the DB so the next request starts clean.
|
||||
if session_id and agent:
|
||||
try:
|
||||
with agent.messages_lock:
|
||||
msg_count = len(agent.messages)
|
||||
if msg_count == 0:
|
||||
from agent.memory import get_conversation_store
|
||||
get_conversation_store().clear_session(session_id)
|
||||
logger.info(f"[AgentBridge] Cleared DB for session after error: {session_id}")
|
||||
except Exception as db_err:
|
||||
logger.warning(f"[AgentBridge] Failed to clear DB after error: {db_err}")
|
||||
return Reply(ReplyType.ERROR, f"Agent error: {str(e)}")
|
||||
|
||||
def _create_file_reply(self, file_info: dict, text_response: str, context: Context = None) -> Reply:
|
||||
|
||||
@@ -130,8 +130,14 @@ class AgentInitializer:
|
||||
Load persisted conversation messages from SQLite and inject them
|
||||
into the agent's in-memory message list.
|
||||
|
||||
Only runs when conversation persistence is enabled (default: True).
|
||||
Respects agent_max_context_turns to limit how many turns are loaded.
|
||||
Only user text and assistant text are restored. Tool call chains
|
||||
(tool_use / tool_result) are stripped out because:
|
||||
1. They are intermediate process, the value is already in the final
|
||||
assistant text reply.
|
||||
2. They consume massive context tokens (often 80%+ of history).
|
||||
3. Different models have incompatible tool message formats, so
|
||||
restoring tool chains across model switches causes 400 errors.
|
||||
4. Eliminates the entire class of tool_use/tool_result pairing bugs.
|
||||
"""
|
||||
from config import conf
|
||||
if not conf().get("conversation_persistence", True):
|
||||
@@ -140,25 +146,99 @@ class AgentInitializer:
|
||||
try:
|
||||
from agent.memory import get_conversation_store
|
||||
store = get_conversation_store()
|
||||
# On restore, load at most min(10, max_turns // 2) turns so that
|
||||
# a long-running session does not immediately fill the context window
|
||||
# after a restart. The full max_turns budget is reserved for the
|
||||
# live conversation that follows.
|
||||
max_turns = conf().get("agent_max_context_turns", 30)
|
||||
restore_turns = max(4, max_turns // 5)
|
||||
max_turns = conf().get("agent_max_context_turns", 20)
|
||||
restore_turns = max(6, max_turns // 5)
|
||||
saved = store.load_messages(session_id, max_turns=restore_turns)
|
||||
if saved:
|
||||
with agent.messages_lock:
|
||||
agent.messages = saved
|
||||
logger.debug(
|
||||
f"[AgentInitializer] Restored {len(saved)} messages "
|
||||
f"({restore_turns} turns cap) for session={session_id}"
|
||||
)
|
||||
filtered = self._filter_text_only_messages(saved)
|
||||
if filtered:
|
||||
with agent.messages_lock:
|
||||
agent.messages = filtered
|
||||
logger.debug(
|
||||
f"[AgentInitializer] Restored {len(filtered)} text messages "
|
||||
f"(from {len(saved)} total, {restore_turns} turns cap) "
|
||||
f"for session={session_id}"
|
||||
)
|
||||
except Exception as e:
|
||||
logger.warning(
|
||||
f"[AgentInitializer] Failed to restore conversation history for "
|
||||
f"session={session_id}: {e}"
|
||||
)
|
||||
|
||||
@staticmethod
|
||||
def _filter_text_only_messages(messages: list) -> list:
|
||||
"""
|
||||
Extract clean user/assistant turn pairs from raw message history.
|
||||
|
||||
Groups messages into turns (each starting with a real user query),
|
||||
then keeps only:
|
||||
- The first user text in each turn (the actual user input)
|
||||
- The last assistant text in each turn (the final answer)
|
||||
|
||||
All tool_use, tool_result, intermediate assistant thoughts, and
|
||||
internal hint messages injected by the agent loop are discarded.
|
||||
"""
|
||||
|
||||
def _extract_text(content) -> str:
|
||||
if isinstance(content, str):
|
||||
return content.strip()
|
||||
if isinstance(content, list):
|
||||
parts = [
|
||||
b.get("text", "")
|
||||
for b in content
|
||||
if isinstance(b, dict) and b.get("type") == "text"
|
||||
]
|
||||
return "\n".join(p for p in parts if p).strip()
|
||||
return ""
|
||||
|
||||
def _is_real_user_msg(msg: dict) -> bool:
|
||||
"""True for actual user input, False for tool_result or internal hints."""
|
||||
if msg.get("role") != "user":
|
||||
return False
|
||||
content = msg.get("content")
|
||||
if isinstance(content, list):
|
||||
has_tool_result = any(
|
||||
isinstance(b, dict) and b.get("type") == "tool_result"
|
||||
for b in content
|
||||
)
|
||||
if has_tool_result:
|
||||
return False
|
||||
text = _extract_text(content)
|
||||
return bool(text)
|
||||
|
||||
# Group into turns: each turn starts with a real user message
|
||||
turns = []
|
||||
current_turn = None
|
||||
for msg in messages:
|
||||
if _is_real_user_msg(msg):
|
||||
if current_turn is not None:
|
||||
turns.append(current_turn)
|
||||
current_turn = {"user": msg, "assistants": []}
|
||||
elif current_turn is not None and msg.get("role") == "assistant":
|
||||
text = _extract_text(msg.get("content"))
|
||||
if text:
|
||||
current_turn["assistants"].append(text)
|
||||
if current_turn is not None:
|
||||
turns.append(current_turn)
|
||||
|
||||
# Build result: one user msg + one assistant msg per turn
|
||||
filtered = []
|
||||
for turn in turns:
|
||||
user_text = _extract_text(turn["user"].get("content"))
|
||||
if not user_text:
|
||||
continue
|
||||
filtered.append({
|
||||
"role": "user",
|
||||
"content": [{"type": "text", "text": user_text}]
|
||||
})
|
||||
if turn["assistants"]:
|
||||
final_reply = turn["assistants"][-1]
|
||||
filtered.append({
|
||||
"role": "assistant",
|
||||
"content": [{"type": "text", "text": final_reply}]
|
||||
})
|
||||
|
||||
return filtered
|
||||
|
||||
def _load_env_file(self):
|
||||
"""Load environment variables from .env file"""
|
||||
|
||||
@@ -192,10 +192,24 @@
|
||||
<i id="theme-icon" class="fas fa-moon"></i>
|
||||
</button>
|
||||
|
||||
<!-- Docs Link -->
|
||||
<a href="https://docs.cowagent.ai" target="_blank" rel="noopener noreferrer"
|
||||
class="p-2 rounded-lg text-slate-500 dark:text-slate-400 hover:bg-slate-100 dark:hover:bg-white/10
|
||||
cursor-pointer transition-colors duration-150" title="Documentation">
|
||||
<i class="fas fa-book text-base"></i>
|
||||
</a>
|
||||
|
||||
<!-- Website Link -->
|
||||
<a href="https://cowagent.ai" target="_blank" rel="noopener noreferrer"
|
||||
class="p-2 rounded-lg text-slate-500 dark:text-slate-400 hover:bg-slate-100 dark:hover:bg-white/10
|
||||
cursor-pointer transition-colors duration-150" title="Website">
|
||||
<i class="fas fa-home text-base"></i>
|
||||
</a>
|
||||
|
||||
<!-- GitHub Link -->
|
||||
<a href="https://github.com/zhayujie/chatgpt-on-wechat" target="_blank" rel="noopener noreferrer"
|
||||
class="p-2 rounded-lg text-slate-500 dark:text-slate-400 hover:bg-slate-100 dark:hover:bg-white/10
|
||||
cursor-pointer transition-colors duration-150">
|
||||
cursor-pointer transition-colors duration-150" title="GitHub">
|
||||
<i class="fab fa-github text-lg"></i>
|
||||
</a>
|
||||
</header>
|
||||
|
||||
@@ -909,7 +909,8 @@ function initConfigView(data) {
|
||||
const providerEl = document.getElementById('cfg-provider');
|
||||
const providerOpts = Object.entries(configProviders).map(([pid, p]) => ({ value: pid, label: p.label }));
|
||||
|
||||
const detected = detectProvider(configCurrentModel);
|
||||
// if use_linkai is enabled, always select linkai as the provider
|
||||
const detected = data.use_linkai ? 'linkai' : detectProvider(configCurrentModel);
|
||||
cfgProviderValue = detected || (providerOpts[0] ? providerOpts[0].value : '');
|
||||
|
||||
initDropdown(providerEl, providerOpts, cfgProviderValue, onProviderChange);
|
||||
|
||||
@@ -522,9 +522,10 @@ class ConfigHandler:
|
||||
"use_agent": use_agent,
|
||||
"title": title,
|
||||
"model": local_config.get("model", ""),
|
||||
"use_linkai": bool(local_config.get("use_linkai", False)),
|
||||
"channel_type": local_config.get("channel_type", ""),
|
||||
"agent_max_context_tokens": local_config.get("agent_max_context_tokens", 50000),
|
||||
"agent_max_context_turns": local_config.get("agent_max_context_turns", 30),
|
||||
"agent_max_context_turns": local_config.get("agent_max_context_turns", 20),
|
||||
"agent_max_steps": local_config.get("agent_max_steps", 15),
|
||||
"api_bases": api_bases,
|
||||
"api_keys": api_keys_masked,
|
||||
|
||||
@@ -7,15 +7,29 @@ description: 将 CowAgent 接入钉钉应用
|
||||
|
||||
## 一、创建应用
|
||||
|
||||
1. 进入 [钉钉开发者后台](https://open-dev.dingtalk.com/fe/app#/corp/app),点击 **创建应用**,填写应用信息
|
||||
2. 点击添加应用能力,选择 **机器人** 能力并添加
|
||||
3. 配置机器人信息后点击 **发布**
|
||||
1. 进入 [钉钉开发者后台](https://open-dev.dingtalk.com/fe/app#/corp/app),登录后点击 **创建应用**,填写应用相关信息:
|
||||
|
||||
<img src="https://img-1317903499.cos.ap-guangzhou.myqcloud.com/docs/dingtalk-create-app.png" width="800"/>
|
||||
|
||||
2. 点击添加应用能力,选择 **机器人** 能力,点击 **添加**:
|
||||
|
||||
<img src="https://img-1317903499.cos.ap-guangzhou.myqcloud.com/docs/dingtalk-add-bot.png" width="800"/>
|
||||
|
||||
3. 配置机器人信息后点击 **发布**。发布后,点击 "**点击调试**",会自动创建测试群聊,可在客户端查看:
|
||||
|
||||
<img src="https://img-1317903499.cos.ap-guangzhou.myqcloud.com/docs/dingtalk-config-bot.png" width="600"/>
|
||||
|
||||
4. 点击 **版本管理与发布**,创建新版本发布:
|
||||
|
||||
<img src="https://img-1317903499.cos.ap-guangzhou.myqcloud.com/docs/dingtalk-publish-bot.png" width="700"/>
|
||||
|
||||
## 二、项目配置
|
||||
|
||||
1. 在 **凭证与基础信息** 中获取 `Client ID` 和 `Client Secret`
|
||||
1. 点击 **凭证与基础信息**,获取 `Client ID` 和 `Client Secret`:
|
||||
|
||||
2. 填入 `config.json`:
|
||||
<img src="https://img-1317903499.cos.ap-guangzhou.myqcloud.com/docs/dingtalk-get-secret.png" width="700"/>
|
||||
|
||||
2. 将以下配置加入项目根目录的 `config.json` 文件:
|
||||
|
||||
```json
|
||||
{
|
||||
@@ -31,8 +45,12 @@ description: 将 CowAgent 接入钉钉应用
|
||||
pip3 install dingtalk_stream
|
||||
```
|
||||
|
||||
4. 启动项目后,在钉钉开发者后台点击 **事件订阅**,点击 **已完成接入,验证连接通道**,显示"连接接入成功"即表示配置完成
|
||||
4. 启动项目后,在钉钉开发者后台点击 **事件订阅**,点击 **已完成接入,验证连接通道**,显示 **连接接入成功** 即表示配置完成:
|
||||
|
||||
<img src="https://img-1317903499.cos.ap-guangzhou.myqcloud.com/docs/dingtalk-event-sub.png" width="700"/>
|
||||
|
||||
## 三、使用
|
||||
|
||||
与机器人私聊或将机器人拉入企业群中均可开启对话。
|
||||
与机器人私聊或将机器人拉入企业群中均可开启对话:
|
||||
|
||||
<img src="https://img-1317903499.cos.ap-guangzhou.myqcloud.com/docs/dingtalk-hosting-demo.png" width="650"/>
|
||||
|
||||
@@ -3,65 +3,67 @@ title: 飞书
|
||||
description: 将 CowAgent 接入飞书应用
|
||||
---
|
||||
|
||||
通过自建应用将 CowAgent 接入飞书,支持 WebSocket 长连接(推荐)和 Webhook 两种事件接收模式。
|
||||
通过自建应用将 CowAgent 接入飞书,需要是飞书企业用户且具有企业管理权限。
|
||||
|
||||
## 一、创建企业自建应用
|
||||
|
||||
### 1. 创建应用
|
||||
|
||||
进入 [飞书开发平台](https://open.feishu.cn/app/),点击 **创建企业自建应用**,填写必要信息后创建。
|
||||
进入 [飞书开发平台](https://open.feishu.cn/app/),点击 **创建企业自建应用**,填写必要信息后点击 **创建**:
|
||||
|
||||
<img src="https://img-1317903499.cos.ap-guangzhou.myqcloud.com/docs/feishu-hosting-create-app.jpg" width="500"/>
|
||||
|
||||
### 2. 添加机器人能力
|
||||
|
||||
在 **添加应用能力** 菜单中,为应用添加 **机器人** 能力。
|
||||
在 **添加应用能力** 菜单中,为应用添加 **机器人** 能力:
|
||||
|
||||
<img src="https://img-1317903499.cos.ap-guangzhou.myqcloud.com/docs/feishu-hosting-add-bot.jpg" width="800"/>
|
||||
|
||||
### 3. 配置应用权限
|
||||
|
||||
点击 **权限管理**,粘贴以下权限配置,全选并批量开通:
|
||||
点击 **权限管理**,复制以下权限配置,粘贴到 **权限配置** 下方的输入框内,全选筛选出来的权限,点击 **批量开通** 并确认:
|
||||
|
||||
```
|
||||
im:message,im:message.group_at_msg,im:message.group_at_msg:readonly,im:message.p2p_msg,im:message.p2p_msg:readonly,im:message:send_as_bot,im:resource
|
||||
```
|
||||
|
||||
<img src="https://cdn.link-ai.tech/doc/feishu-hosting-add-auth2.png" width="800"/>
|
||||
|
||||
## 二、项目配置
|
||||
|
||||
在 **凭证与基础信息** 中获取 `App ID` 和 `App Secret`,填入 `config.json`:
|
||||
1. 在 **凭证与基础信息** 中获取 `App ID` 和 `App Secret`:
|
||||
|
||||
<Tabs>
|
||||
<Tab title="WebSocket 模式(推荐)">
|
||||
无需公网 IP,配置如下:
|
||||
<img src="https://img-1317903499.cos.ap-guangzhou.myqcloud.com/docs/feishu-hosting-appid-secret.jpg" width="800"/>
|
||||
|
||||
```json
|
||||
{
|
||||
"channel_type": "feishu",
|
||||
"feishu_app_id": "YOUR_APP_ID",
|
||||
"feishu_app_secret": "YOUR_APP_SECRET",
|
||||
"feishu_event_mode": "websocket"
|
||||
}
|
||||
```
|
||||
2. 将以下配置加入项目根目录的 `config.json` 文件:
|
||||
|
||||
需安装依赖:`pip3 install lark-oapi`
|
||||
</Tab>
|
||||
<Tab title="Webhook 模式">
|
||||
需要公网 IP,配置如下:
|
||||
```json
|
||||
{
|
||||
"channel_type": "feishu",
|
||||
"feishu_app_id": "YOUR_APP_ID",
|
||||
"feishu_app_secret": "YOUR_APP_SECRET",
|
||||
"feishu_bot_name": "YOUR_BOT_NAME"
|
||||
}
|
||||
```
|
||||
|
||||
```json
|
||||
{
|
||||
"channel_type": "feishu",
|
||||
"feishu_app_id": "YOUR_APP_ID",
|
||||
"feishu_app_secret": "YOUR_APP_SECRET",
|
||||
"feishu_token": "VERIFICATION_TOKEN",
|
||||
"feishu_event_mode": "webhook",
|
||||
"feishu_port": 9891
|
||||
}
|
||||
```
|
||||
</Tab>
|
||||
</Tabs>
|
||||
| 参数 | 说明 |
|
||||
| --- | --- |
|
||||
| `feishu_app_id` | 飞书机器人应用 App ID |
|
||||
| `feishu_app_secret` | 飞书机器人 App Secret |
|
||||
| `feishu_bot_name` | 飞书机器人名称(创建应用时设置),群聊中使用依赖此配置 |
|
||||
|
||||
配置完成后启动项目。
|
||||
|
||||
## 三、配置事件订阅
|
||||
|
||||
1. 启动项目后,在飞书开放平台点击 **事件与回调**,选择 **长连接** 方式并保存
|
||||
2. 点击 **添加事件**,搜索 "接收消息",选择 "接收消息v2.0",确认添加
|
||||
3. 点击 **版本管理与发布**,创建版本并申请线上发布,审核通过后即可使用
|
||||
1. 成功运行项目后,在飞书开放平台点击 **事件与回调**,选择 **长连接** 方式,点击保存:
|
||||
|
||||
<img src="https://cdn.link-ai.tech/doc/202601311731183.png" width="600"/>
|
||||
|
||||
2. 点击下方的 **添加事件**,搜索 "接收消息",选择 "**接收消息v2.0**",确认添加。
|
||||
|
||||
3. 点击 **版本管理与发布**,创建版本并申请 **线上发布**,在飞书客户端查看审批消息并审核通过:
|
||||
|
||||
<img src="https://cdn.link-ai.tech/doc/202601311807356.png" width="600"/>
|
||||
|
||||
完成后在飞书中搜索机器人名称,即可开始对话。
|
||||
|
||||
@@ -1,9 +1,9 @@
|
||||
---
|
||||
title: Web 网页
|
||||
description: 通过 Web 网页端使用 CowAgent
|
||||
title: Web 控制台
|
||||
description: 通过 Web 控制台使用 CowAgent
|
||||
---
|
||||
|
||||
Web 是 CowAgent 的默认通道,启动后会自动运行 Web 控制台,通过浏览器即可与 Agent 对话。
|
||||
Web 控制台是 CowAgent 的默认通道,启动后会自动运行,通过浏览器即可与 Agent 对话,并支持在线管理模型、技能、记忆、通道等配置。
|
||||
|
||||
## 配置
|
||||
|
||||
@@ -19,13 +19,57 @@ Web 是 CowAgent 的默认通道,启动后会自动运行 Web 控制台,通
|
||||
| `channel_type` | 设为 `web` | `web` |
|
||||
| `web_port` | Web 服务监听端口 | `9899` |
|
||||
|
||||
## 使用
|
||||
## 访问地址
|
||||
|
||||
启动项目后访问:
|
||||
|
||||
- 本地运行:`http://localhost:9899/chat`
|
||||
- 服务器运行:`http://<server-ip>:9899/chat`
|
||||
- 本地运行:`http://localhost:9899`
|
||||
- 服务器运行:`http://<server-ip>:9899`
|
||||
|
||||
<Note>
|
||||
请确保服务器防火墙和安全组已放行对应端口。
|
||||
</Note>
|
||||
|
||||
## 功能介绍
|
||||
|
||||
### 对话界面
|
||||
|
||||
支持流式输出,可实时展示 Agent 的思考过程(Reasoning)和工具调用过程(Tool Calls),更直观地观察 Agent 的决策过程:
|
||||
|
||||
<img width="850" src="https://cdn.link-ai.tech/doc/20260227180120.png" />
|
||||
|
||||
### 模型管理
|
||||
|
||||
支持在线管理模型配置,无需手动编辑配置文件:
|
||||
|
||||
<img width="850" src="https://cdn.link-ai.tech/doc/20260227173811.png" />
|
||||
|
||||
### 技能管理
|
||||
|
||||
支持在线查看和管理 Agent 技能(Skills):
|
||||
|
||||
<img width="850" src="https://cdn.link-ai.tech/doc/20260227173403.png" />
|
||||
|
||||
### 记忆管理
|
||||
|
||||
支持在线查看和管理 Agent 记忆:
|
||||
|
||||
<img width="850" src="https://cdn.link-ai.tech/doc/20260227173349.png" />
|
||||
|
||||
### 通道管理
|
||||
|
||||
支持在线管理接入通道,支持实时连接/断开操作:
|
||||
|
||||
<img width="850" src="https://cdn.link-ai.tech/doc/20260227173331.png" />
|
||||
|
||||
### 定时任务
|
||||
|
||||
支持在线查看和管理定时任务,包括一次性任务、固定间隔、Cron 表达式等多种调度方式的可视化管理:
|
||||
|
||||
<img width="850" src="https://cdn.link-ai.tech/doc/20260227173704.png" />
|
||||
|
||||
### 日志
|
||||
|
||||
支持在线实时查看 Agent 运行日志,便于监控运行状态和排查问题:
|
||||
|
||||
<img width="850" src="https://cdn.link-ai.tech/doc/20260227173514.png" />
|
||||
|
||||
@@ -7,21 +7,22 @@ CowAgent 支持接入个人订阅号和企业服务号两种公众号类型。
|
||||
|
||||
| 类型 | 要求 | 特点 |
|
||||
| --- | --- | --- |
|
||||
| **个人订阅号** | 个人可申请 | 回复生成后需用户主动发消息获取 |
|
||||
| **个人订阅号** | 个人可申请 | 收到消息时会回复一条提示,回复生成后需用户主动发消息获取 |
|
||||
| **企业服务号** | 企业申请,需通过微信认证开通客服接口 | 回复生成后可主动推送给用户 |
|
||||
|
||||
<Note>
|
||||
公众号仅支持服务器和 Docker 部署,需额外安装扩展依赖:`pip3 install -r requirements-optional.txt`
|
||||
公众号仅支持服务器和 Docker 部署,不支持本地运行。需额外安装扩展依赖:`pip3 install -r requirements-optional.txt`
|
||||
</Note>
|
||||
|
||||
## 一、个人订阅号
|
||||
|
||||
在 `config.json` 中配置:
|
||||
在 `config.json` 中添加以下配置:
|
||||
|
||||
```json
|
||||
{
|
||||
"channel_type": "wechatmp",
|
||||
"wechatmp_app_id": "YOUR_APP_ID",
|
||||
"single_chat_prefix": [""],
|
||||
"wechatmp_app_id": "wx73f9******d1e48",
|
||||
"wechatmp_app_secret": "YOUR_APP_SECRET",
|
||||
"wechatmp_aes_key": "",
|
||||
"wechatmp_token": "YOUR_TOKEN",
|
||||
@@ -31,22 +32,37 @@ CowAgent 支持接入个人订阅号和企业服务号两种公众号类型。
|
||||
|
||||
### 配置步骤
|
||||
|
||||
1. 在 [微信公众平台](https://mp.weixin.qq.com/) 的 **设置与开发 → 基本配置 → 服务器配置** 中获取参数
|
||||
2. 启用开发者密码,将服务器 IP 加入白名单
|
||||
3. 启动程序(监听 80 端口)
|
||||
4. 在公众号后台 **启用服务器配置**,URL 格式为 `http://{HOST}/wx`
|
||||
这些配置需要和 [微信公众号后台](https://mp.weixin.qq.com/advanced/advanced?action=dev&t=advanced/dev) 中的保持一致,进入页面后,在左侧菜单选择 **设置与开发 → 基本配置 → 服务器配置**,按下图进行配置:
|
||||
|
||||
<img src="https://cdn.link-ai.tech/doc/20260228103506.png" width="480"/>
|
||||
|
||||
1. 在公众平台启用开发者密码(对应配置 `wechatmp_app_secret`),并将服务器 IP 填入白名单
|
||||
2. 按上图填写 `config.json` 中与公众号相关的配置,要与公众号后台的配置一致
|
||||
3. 启动程序,启动后会监听 80 端口(若无权限监听,则在启动命令前加上 `sudo`;若 80 端口已被占用,则关闭该占用进程)
|
||||
4. 在公众号后台 **启用服务器配置** 并提交,保存成功则表示已成功配置。注意 **"服务器地址(URL)"** 需要配置为 `http://{HOST}/wx` 的格式,其中 `{HOST}` 可以是服务器的 IP 或域名
|
||||
|
||||
随后关注公众号并发送消息即可看到以下效果:
|
||||
|
||||
<img src="https://cdn.link-ai.tech/doc/20260228103522.png" width="720"/>
|
||||
|
||||
由于受订阅号限制,回复内容较短的情况下(15s 内),可以立即完成回复,但耗时较长的回复则会先回复一句 "正在思考中",后续需要用户输入任意文字主动获取答案,而服务号则可以通过客服接口解决这一问题。
|
||||
|
||||
<Tip>
|
||||
**语音识别**:可利用微信自带的语音识别功能,需要在公众号管理页面的 "设置与开发 → 接口权限" 页面开启 "接收语音识别结果"。
|
||||
</Tip>
|
||||
|
||||
## 二、企业服务号
|
||||
|
||||
与个人订阅号流程基本相同,差异如下:
|
||||
企业服务号与上述个人订阅号的接入过程基本相同,差异如下:
|
||||
|
||||
1. 在公众平台申请企业服务号并完成微信认证,确认已获得 **客服接口** 权限
|
||||
2. 在 `config.json` 中设置 `"channel_type": "wechatmp_service"`
|
||||
3. 即使是较长耗时的回复,也可以主动推送给用户
|
||||
1. 在公众平台申请企业服务号并完成微信认证,在接口权限中确认已获得 **客服接口** 的权限
|
||||
2. 在 `config.json` 中设置 `"channel_type": "wechatmp_service"`,其他配置与上述订阅号相同
|
||||
3. 交互效果上,即使是较长耗时的回复,也可以主动推送给用户,无需用户手动获取
|
||||
|
||||
```json
|
||||
{
|
||||
"channel_type": "wechatmp_service",
|
||||
"single_chat_prefix": [""],
|
||||
"wechatmp_app_id": "YOUR_APP_ID",
|
||||
"wechatmp_app_secret": "YOUR_APP_SECRET",
|
||||
"wechatmp_aes_key": "",
|
||||
|
||||
@@ -19,17 +19,35 @@ description: 将 CowAgent 接入企业微信自建应用
|
||||
|
||||
## 二、创建企业微信应用
|
||||
|
||||
1. 在 [企业微信管理后台](https://work.weixin.qq.com/wework_admin/frame#profile) **我的企业** 中获取 **企业ID**
|
||||
2. 切换到 **应用管理**,点击创建应用,记录 `AgentId` 和 `Secret`
|
||||
3. 点击 **设置API接收**,配置应用接口:
|
||||
- URL 格式为 `http://ip:port/wxcomapp`(认证企业需使用备案域名)
|
||||
- 随机获取 `Token` 和 `EncodingAESKey` 并保存
|
||||
1. 在 [企业微信管理后台](https://work.weixin.qq.com/wework_admin/frame#profile) 点击 **我的企业**,在最下方获取 **企业ID**(后续填写到 `wechatcom_corp_id` 字段中)。
|
||||
|
||||
2. 切换到 **应用管理**,点击创建应用:
|
||||
|
||||
<img src="https://cdn.link-ai.tech/doc/20260228103156.png" width="480"/>
|
||||
|
||||
3. 进入应用创建页面,记录 `AgentId` 和 `Secret`:
|
||||
|
||||
<img src="https://cdn.link-ai.tech/doc/20260228103218.png" width="580"/>
|
||||
|
||||
4. 点击 **设置API接收**,配置应用接口:
|
||||
|
||||
<img src="https://cdn.link-ai.tech/doc/20260228103211.png" width="520"/>
|
||||
|
||||
- URL 格式为 `http://ip:port/wxcomapp`(认证企业需使用备案域名)
|
||||
- 随机获取 `Token` 和 `EncodingAESKey` 并保存
|
||||
|
||||
<Note>
|
||||
此时保存 API 接收配置会失败,因为程序还未启动,等项目运行后再回来保存。
|
||||
</Note>
|
||||
|
||||
## 三、配置和运行
|
||||
|
||||
在 `config.json` 中添加以下配置(各参数与企业微信后台的对应关系见上方截图):
|
||||
|
||||
```json
|
||||
{
|
||||
"channel_type": "wechatcom_app",
|
||||
"single_chat_prefix": [""],
|
||||
"wechatcom_corp_id": "YOUR_CORP_ID",
|
||||
"wechatcomapp_token": "YOUR_TOKEN",
|
||||
"wechatcomapp_secret": "YOUR_SECRET",
|
||||
@@ -48,12 +66,25 @@ description: 将 CowAgent 接入企业微信自建应用
|
||||
| `wechatcomapp_aes_key` | API 接收配置中的 EncodingAESKey |
|
||||
| `wechatcomapp_port` | 监听端口,默认 9898 |
|
||||
|
||||
启动程序后,回到企业微信后台保存 **消息服务器配置**,并将服务器 IP 添加到 **企业可信IP** 中。
|
||||
配置完成后启动程序。当后台日志显示 `http://0.0.0.0:9898/` 时说明程序运行成功,需要将该端口对外开放(如在云服务器安全组中放行)。
|
||||
|
||||
程序启动后,回到企业微信后台保存 **消息服务器配置**,保存成功后还需将服务器 IP 添加到 **企业可信IP** 中,否则无法收发消息:
|
||||
|
||||
<img src="https://cdn.link-ai.tech/doc/20260228103224.png" width="520"/>
|
||||
|
||||
<Warning>
|
||||
如遇到配置失败:1. 确保防火墙和安全组已放行端口;2. 检查各参数配置是否一致;3. 认证企业需配置备案域名。
|
||||
如遇到 URL 配置回调不通过或配置失败:
|
||||
1. 确保服务器防火墙关闭且安全组放行监听端口
|
||||
2. 仔细检查 Token、Secret Key 等参数配置是否一致,URL 格式是否正确
|
||||
3. 认证企业微信需要配置与主体一致的备案域名
|
||||
</Warning>
|
||||
|
||||
## 四、使用
|
||||
|
||||
在企业微信中搜索应用名称即可直接对话。如需让外部微信用户使用,可在 **我的企业 → 微信插件** 中分享邀请关注二维码。
|
||||
在企业微信中搜索刚创建的应用名称,即可直接对话:
|
||||
|
||||
<img src="https://cdn.link-ai.tech/doc/20260228103228.png" width="720"/>
|
||||
|
||||
如需让外部个人微信用户使用,可在 **我的企业 → 微信插件** 中分享邀请关注二维码,个人微信扫码关注后即可与应用对话:
|
||||
|
||||
<img src="https://cdn.link-ai.tech/doc/20260228103232.png" width="520"/>
|
||||
|
||||
@@ -311,6 +311,7 @@
|
||||
"group": "Release Notes",
|
||||
"pages": [
|
||||
"en/releases/overview",
|
||||
"en/releases/v2.0.2",
|
||||
"en/releases/v2.0.1",
|
||||
"en/releases/v2.0.0"
|
||||
]
|
||||
|
||||
@@ -35,6 +35,10 @@
|
||||
|
||||
## Changelog
|
||||
|
||||
> **2026.02.27:** [v2.0.2](https://github.com/zhayujie/chatgpt-on-wechat/releases/tag/2.0.2) — Web console overhaul (streaming chat, model/skill/memory/channel/scheduler/log management), multi-channel concurrent running, session persistence, new models including Gemini 3.1 Pro / Claude 4.6 Sonnet / Qwen3.5 Plus.
|
||||
|
||||
> **2026.02.13:** [v2.0.1](https://github.com/zhayujie/chatgpt-on-wechat/releases/tag/2.0.1) — Built-in Web Search tool, smart context trimming, runtime info dynamic update, Windows compatibility, fixes for scheduler memory loss, Feishu connection issues, and more.
|
||||
|
||||
> **2026.02.03:** [v2.0.0](https://github.com/zhayujie/chatgpt-on-wechat/releases/tag/2.0.0) — Full upgrade to AI super assistant with multi-step task planning, long-term memory, built-in tools, Skills framework, new models, and optimized channels.
|
||||
|
||||
> **2025.05.23:** [v1.7.6](https://github.com/zhayujie/chatgpt-on-wechat/releases/tag/1.7.6) — Web channel optimization, AgentMesh multi-agent plugin, Baidu TTS, claude-4-sonnet/opus support.
|
||||
|
||||
@@ -7,15 +7,29 @@ Integrate CowAgent into DingTalk by creating an intelligent robot app on the Din
|
||||
|
||||
## 1. Create App
|
||||
|
||||
1. Go to [DingTalk Developer Console](https://open-dev.dingtalk.com/fe/app#/corp/app), click **Create App**, fill in app information
|
||||
2. Click **Add App Capability**, select **Robot** capability and add
|
||||
3. Configure robot information and click **Publish**
|
||||
1. Go to [DingTalk Developer Console](https://open-dev.dingtalk.com/fe/app#/corp/app), log in and click **Create App**, fill in the app information:
|
||||
|
||||
<img src="https://img-1317903499.cos.ap-guangzhou.myqcloud.com/docs/dingtalk-create-app.png" width="800"/>
|
||||
|
||||
2. Click **Add App Capability**, select **Robot** capability and click **Add**:
|
||||
|
||||
<img src="https://img-1317903499.cos.ap-guangzhou.myqcloud.com/docs/dingtalk-add-bot.png" width="800"/>
|
||||
|
||||
3. Configure the robot information and click **Publish**. After publishing, click "**Debug**" to automatically create a test group chat, which can be viewed in the client:
|
||||
|
||||
<img src="https://img-1317903499.cos.ap-guangzhou.myqcloud.com/docs/dingtalk-config-bot.png" width="600"/>
|
||||
|
||||
4. Click **Version Management & Release**, create a new version and publish:
|
||||
|
||||
<img src="https://img-1317903499.cos.ap-guangzhou.myqcloud.com/docs/dingtalk-publish-bot.png" width="700"/>
|
||||
|
||||
## 2. Project Configuration
|
||||
|
||||
1. Get `Client ID` and `Client Secret` from **Credentials & Basic Info**
|
||||
1. Click **Credentials & Basic Info**, get the `Client ID` and `Client Secret`:
|
||||
|
||||
2. Fill in `config.json`:
|
||||
<img src="https://img-1317903499.cos.ap-guangzhou.myqcloud.com/docs/dingtalk-get-secret.png" width="700"/>
|
||||
|
||||
2. Add the following configuration to `config.json` in the project root:
|
||||
|
||||
```json
|
||||
{
|
||||
@@ -25,14 +39,20 @@ Integrate CowAgent into DingTalk by creating an intelligent robot app on the Din
|
||||
}
|
||||
```
|
||||
|
||||
3. Install dependency:
|
||||
3. Install the dependency:
|
||||
|
||||
```bash
|
||||
pip3 install dingtalk_stream
|
||||
```
|
||||
|
||||
4. After starting the project, go to DingTalk Developer Console **Event Subscription**, click **Connection verified, verify channel**. When "Connection successful" is displayed, configuration is complete
|
||||
<img src="https://img-1317903499.cos.ap-guangzhou.myqcloud.com/docs/dingtalk-app-config.png" width="700"/>
|
||||
|
||||
4. After starting the project, go to the DingTalk Developer Console, click **Event Subscription**, then click **Connection verified, verify channel**. When "**Connection successful**" is displayed, the configuration is complete:
|
||||
|
||||
<img src="https://img-1317903499.cos.ap-guangzhou.myqcloud.com/docs/dingtalk-event-sub.png" width="700"/>
|
||||
|
||||
## 3. Usage
|
||||
|
||||
Chat privately with the robot or add it to an enterprise group to start a conversation.
|
||||
Chat privately with the robot or add it to an enterprise group to start a conversation:
|
||||
|
||||
<img src="https://img-1317903499.cos.ap-guangzhou.myqcloud.com/docs/dingtalk-hosting-demo.png" width="650"/>
|
||||
|
||||
@@ -3,65 +3,67 @@ title: Feishu (Lark)
|
||||
description: Integrate CowAgent into Feishu application
|
||||
---
|
||||
|
||||
Integrate CowAgent into Feishu by creating a custom app. Supports WebSocket (recommended, no public IP required) and Webhook event receiving modes.
|
||||
Integrate CowAgent into Feishu by creating a custom enterprise app. You need to be a Feishu enterprise user with admin privileges.
|
||||
|
||||
## 1. Create Enterprise Custom App
|
||||
|
||||
### 1.1 Create App
|
||||
|
||||
Go to [Feishu Developer Platform](https://open.feishu.cn/app/), click **Create Enterprise Custom App**, fill in the required information and create.
|
||||
Go to [Feishu Developer Platform](https://open.feishu.cn/app/), click **Create Enterprise Custom App**, fill in the required information and click **Create**:
|
||||
|
||||
<img src="https://img-1317903499.cos.ap-guangzhou.myqcloud.com/docs/feishu-hosting-create-app.jpg" width="500"/>
|
||||
|
||||
### 1.2 Add Bot Capability
|
||||
|
||||
In **Add App Capabilities**, add **Bot** capability to the app.
|
||||
In **Add App Capabilities**, add **Bot** capability to the app:
|
||||
|
||||
<img src="https://img-1317903499.cos.ap-guangzhou.myqcloud.com/docs/feishu-hosting-add-bot.jpg" width="800"/>
|
||||
|
||||
### 1.3 Configure App Permissions
|
||||
|
||||
Click **Permission Management**, paste the following permission string, select all and enable in batch:
|
||||
Click **Permission Management**, paste the following permission string into the input box below **Permission Configuration**, select all filtered permissions, click **Batch Enable** and confirm:
|
||||
|
||||
```
|
||||
im:message,im:message.group_at_msg,im:message.group_at_msg:readonly,im:message.p2p_msg,im:message.p2p_msg:readonly,im:message:send_as_bot,im:resource
|
||||
```
|
||||
|
||||
<img src="https://cdn.link-ai.tech/doc/feishu-hosting-add-auth2.png" width="800"/>
|
||||
|
||||
## 2. Project Configuration
|
||||
|
||||
Get `App ID` and `App Secret` from **Credentials & Basic Info**, then fill in `config.json`:
|
||||
1. Get `App ID` and `App Secret` from **Credentials & Basic Info**:
|
||||
|
||||
<Tabs>
|
||||
<Tab title="WebSocket Mode (Recommended)">
|
||||
No public IP required. Configuration:
|
||||
<img src="https://img-1317903499.cos.ap-guangzhou.myqcloud.com/docs/feishu-hosting-appid-secret.jpg" width="800"/>
|
||||
|
||||
```json
|
||||
{
|
||||
"channel_type": "feishu",
|
||||
"feishu_app_id": "YOUR_APP_ID",
|
||||
"feishu_app_secret": "YOUR_APP_SECRET",
|
||||
"feishu_event_mode": "websocket"
|
||||
}
|
||||
```
|
||||
2. Add the following configuration to `config.json` in the project root:
|
||||
|
||||
Install dependency: `pip3 install lark-oapi`
|
||||
</Tab>
|
||||
<Tab title="Webhook Mode">
|
||||
Requires public IP. Configuration:
|
||||
```json
|
||||
{
|
||||
"channel_type": "feishu",
|
||||
"feishu_app_id": "YOUR_APP_ID",
|
||||
"feishu_app_secret": "YOUR_APP_SECRET",
|
||||
"feishu_bot_name": "YOUR_BOT_NAME"
|
||||
}
|
||||
```
|
||||
|
||||
```json
|
||||
{
|
||||
"channel_type": "feishu",
|
||||
"feishu_app_id": "YOUR_APP_ID",
|
||||
"feishu_app_secret": "YOUR_APP_SECRET",
|
||||
"feishu_token": "VERIFICATION_TOKEN",
|
||||
"feishu_event_mode": "webhook",
|
||||
"feishu_port": 9891
|
||||
}
|
||||
```
|
||||
</Tab>
|
||||
</Tabs>
|
||||
| Parameter | Description |
|
||||
| --- | --- |
|
||||
| `feishu_app_id` | Feishu bot App ID |
|
||||
| `feishu_app_secret` | Feishu bot App Secret |
|
||||
| `feishu_bot_name` | Bot name (set when creating the app), required for group chat usage |
|
||||
|
||||
Start the project after configuration is complete.
|
||||
|
||||
## 3. Configure Event Subscription
|
||||
|
||||
1. After starting the project, go to Feishu Developer Platform **Events & Callbacks**, select **Long Connection** and save
|
||||
2. Click **Add Event**, search for "Receive Message", select "Receive Message v2.0", confirm and add
|
||||
3. Click **Version Management & Release**, create a version and apply for production release. After approval, you can use it
|
||||
1. After the project is running successfully, go to the Feishu Developer Platform, click **Events & Callbacks**, select **Long Connection** mode, and click save:
|
||||
|
||||
Search for the bot name in Feishu to start chatting.
|
||||
<img src="https://cdn.link-ai.tech/doc/202601311731183.png" width="600"/>
|
||||
|
||||
2. Click **Add Event** below, search for "Receive Message", select "**Receive Message v2.0**", and confirm.
|
||||
|
||||
3. Click **Version Management & Release**, create a new version and apply for **Production Release**. Check the approval message in the Feishu client and approve:
|
||||
|
||||
<img src="https://cdn.link-ai.tech/doc/202601311807356.png" width="600"/>
|
||||
|
||||
Once completed, search for the bot name in Feishu to start chatting.
|
||||
|
||||
@@ -1,9 +1,9 @@
|
||||
---
|
||||
title: Web
|
||||
description: Use CowAgent through the web interface
|
||||
title: Web Console
|
||||
description: Use CowAgent through the web console
|
||||
---
|
||||
|
||||
Web is CowAgent's default channel. The web console starts automatically after launch, allowing you to chat with the Agent through a browser.
|
||||
The Web Console is CowAgent's default channel. It starts automatically after launch, allowing you to chat with the Agent through a browser and manage models, skills, memory, channels, and other configurations online.
|
||||
|
||||
## Configuration
|
||||
|
||||
@@ -19,13 +19,57 @@ Web is CowAgent's default channel. The web console starts automatically after la
|
||||
| `channel_type` | Set to `web` | `web` |
|
||||
| `web_port` | Web service listen port | `9899` |
|
||||
|
||||
## Usage
|
||||
## Access URL
|
||||
|
||||
After starting the project, visit:
|
||||
|
||||
- Local: `http://localhost:9899/chat`
|
||||
- Server: `http://<server-ip>:9899/chat`
|
||||
- Local: `http://localhost:9899`
|
||||
- Server: `http://<server-ip>:9899`
|
||||
|
||||
<Note>
|
||||
Ensure the server firewall and security group allow the corresponding port.
|
||||
</Note>
|
||||
|
||||
## Features
|
||||
|
||||
### Chat Interface
|
||||
|
||||
Supports streaming output with real-time display of the Agent's reasoning process and tool calls, providing intuitive observation of the Agent's decision-making:
|
||||
|
||||
<img width="850" src="https://cdn.link-ai.tech/doc/20260227180120.png" />
|
||||
|
||||
### Model Management
|
||||
|
||||
Manage model configurations online without manually editing config files:
|
||||
|
||||
<img width="850" src="https://cdn.link-ai.tech/doc/20260227173811.png" />
|
||||
|
||||
### Skill Management
|
||||
|
||||
View and manage Agent skills (Skills) online:
|
||||
|
||||
<img width="850" src="https://cdn.link-ai.tech/doc/20260227173403.png" />
|
||||
|
||||
### Memory Management
|
||||
|
||||
View and manage Agent memory online:
|
||||
|
||||
<img width="850" src="https://cdn.link-ai.tech/doc/20260227173349.png" />
|
||||
|
||||
### Channel Management
|
||||
|
||||
Manage connected channels online with real-time connect/disconnect operations:
|
||||
|
||||
<img width="850" src="https://cdn.link-ai.tech/doc/20260227173331.png" />
|
||||
|
||||
### Scheduled Tasks
|
||||
|
||||
View and manage scheduled tasks online, including one-time tasks, fixed intervals, and Cron expressions:
|
||||
|
||||
<img width="850" src="https://cdn.link-ai.tech/doc/20260227173704.png" />
|
||||
|
||||
### Logs
|
||||
|
||||
View Agent runtime logs in real-time for monitoring and troubleshooting:
|
||||
|
||||
<img width="850" src="https://cdn.link-ai.tech/doc/20260227173514.png" />
|
||||
|
||||
@@ -7,19 +7,22 @@ CowAgent supports both personal subscription accounts and enterprise service acc
|
||||
|
||||
| Type | Requirements | Features |
|
||||
| --- | --- | --- |
|
||||
| **Personal Subscription** | Available to individuals | Users must send a message to retrieve replies |
|
||||
| **Personal Subscription** | Available to individuals | Sends a placeholder reply first; users must send a message to retrieve the full response |
|
||||
| **Enterprise Service** | Enterprise with verified customer service API | Can proactively push replies to users |
|
||||
|
||||
<Note>
|
||||
Official Accounts only support server and Docker deployment. Install extended dependencies: `pip3 install -r requirements-optional.txt`
|
||||
Official Accounts only support server and Docker deployment, not local run mode. Install extended dependencies: `pip3 install -r requirements-optional.txt`
|
||||
</Note>
|
||||
|
||||
## Personal Subscription Account
|
||||
## 1. Personal Subscription Account
|
||||
|
||||
Add the following configuration to `config.json`:
|
||||
|
||||
```json
|
||||
{
|
||||
"channel_type": "wechatmp",
|
||||
"wechatmp_app_id": "YOUR_APP_ID",
|
||||
"single_chat_prefix": [""],
|
||||
"wechatmp_app_id": "wx73f9******d1e48",
|
||||
"wechatmp_app_secret": "YOUR_APP_SECRET",
|
||||
"wechatmp_aes_key": "",
|
||||
"wechatmp_token": "YOUR_TOKEN",
|
||||
@@ -29,22 +32,37 @@ CowAgent supports both personal subscription accounts and enterprise service acc
|
||||
|
||||
### Setup Steps
|
||||
|
||||
1. Get parameters from [WeChat Official Account Platform](https://mp.weixin.qq.com/) under **Settings & Development → Basic Configuration → Server Configuration**
|
||||
2. Enable developer secret and add server IP to the whitelist
|
||||
3. Start the program (listens on port 80)
|
||||
4. Enable server configuration with URL format `http://{HOST}/wx`
|
||||
These configurations must be consistent with the [WeChat Official Account Platform](https://mp.weixin.qq.com/advanced/advanced?action=dev&t=advanced/dev). Navigate to **Settings & Development → Basic Configuration → Server Configuration** and configure as shown below:
|
||||
|
||||
## Enterprise Service Account
|
||||
<img src="https://cdn.link-ai.tech/doc/20260228103506.png" width="480"/>
|
||||
|
||||
Same setup with these differences:
|
||||
1. Enable the developer secret on the platform (corresponds to `wechatmp_app_secret`), and add the server IP to the whitelist
|
||||
2. Fill in the `config.json` with the official account parameters matching the platform configuration
|
||||
3. Start the program, which listens on port 80 (use `sudo` if you don't have permission; stop any process occupying port 80)
|
||||
4. **Enable server configuration** on the official account platform and submit. A successful save means the configuration is complete. Note that the **"Server URL"** must be in the format `http://{HOST}/wx`, where `{HOST}` can be the server IP or domain
|
||||
|
||||
1. Register an enterprise service account with verified **Customer Service API** permission
|
||||
2. Set `"channel_type": "wechatmp_service"` in `config.json`
|
||||
3. Replies can be proactively pushed to users
|
||||
After following the account and sending a message, you should see the following result:
|
||||
|
||||
<img src="https://cdn.link-ai.tech/doc/20260228103522.png" width="720"/>
|
||||
|
||||
Due to subscription account limitations, short replies (within 15s) can be returned immediately, but longer replies will first send a "Thinking..." placeholder, requiring users to send any text to retrieve the answer. Enterprise service accounts can solve this with the customer service API.
|
||||
|
||||
<Tip>
|
||||
**Voice Recognition**: You can use WeChat's built-in voice recognition. Enable "Receive Voice Recognition Results" under "Settings & Development → API Permissions" on the official account management page.
|
||||
</Tip>
|
||||
|
||||
## 2. Enterprise Service Account
|
||||
|
||||
The setup process for enterprise service accounts is essentially the same as personal subscription accounts, with the following differences:
|
||||
|
||||
1. Register an enterprise service account on the platform and complete WeChat certification. Confirm that the **Customer Service API** permission has been granted
|
||||
2. Set `"channel_type": "wechatmp_service"` in `config.json`; other configurations remain the same
|
||||
3. Even for longer replies, they can be proactively pushed to users without requiring manual retrieval
|
||||
|
||||
```json
|
||||
{
|
||||
"channel_type": "wechatmp_service",
|
||||
"single_chat_prefix": [""],
|
||||
"wechatmp_app_id": "YOUR_APP_ID",
|
||||
"wechatmp_app_secret": "YOUR_APP_SECRET",
|
||||
"wechatmp_aes_key": "",
|
||||
|
||||
@@ -13,23 +13,41 @@ Integrate CowAgent into WeCom through a custom enterprise app, supporting one-on
|
||||
|
||||
Required resources:
|
||||
|
||||
1. A server with public IP
|
||||
2. A registered WeCom account (individual registration is possible, but cannot be certified)
|
||||
3. Certified WeCom requires a domain with corresponding entity filing
|
||||
1. A server with public IP (overseas server, or domestic server with a proxy for international API access)
|
||||
2. A registered WeCom account (individual registration is possible but cannot be certified)
|
||||
3. Certified WeCom accounts additionally require a domain filed under the corresponding entity
|
||||
|
||||
## 2. Create WeCom App
|
||||
|
||||
1. Get **Corp ID** from **My Enterprise** in [WeCom Admin Console](https://work.weixin.qq.com/wework_admin/frame#profile)
|
||||
2. Switch to **Application Management**, click Create Application, record `AgentId` and `Secret`
|
||||
3. Click **Set API Reception**, configure application interface:
|
||||
- URL format: `http://ip:port/wxcomapp` (certified enterprises must use filed domain)
|
||||
- Generate random `Token` and `EncodingAESKey` and save
|
||||
1. In the [WeCom Admin Console](https://work.weixin.qq.com/wework_admin/frame#profile), click **My Enterprise** and find the **Corp ID** at the bottom of the page. Save this ID for the `wechatcom_corp_id` configuration field.
|
||||
|
||||
2. Switch to **Application Management** and click Create Application:
|
||||
|
||||
<img src="https://cdn.link-ai.tech/doc/20260228103156.png" width="480"/>
|
||||
|
||||
3. On the application creation page, record the `AgentId` and `Secret`:
|
||||
|
||||
<img src="https://cdn.link-ai.tech/doc/20260228103218.png" width="580"/>
|
||||
|
||||
4. Click **Set API Reception** to configure the application interface:
|
||||
|
||||
<img src="https://cdn.link-ai.tech/doc/20260228103211.png" width="520"/>
|
||||
|
||||
- URL format: `http://ip:port/wxcomapp` (certified enterprises must use a filed domain)
|
||||
- Generate random `Token` and `EncodingAESKey` and save them for the configuration file
|
||||
|
||||
<Note>
|
||||
The API reception configuration cannot be saved at this point because the program hasn't started yet. Come back to save it after the project is running.
|
||||
</Note>
|
||||
|
||||
## 3. Configuration and Run
|
||||
|
||||
Add the following configuration to `config.json` (the mapping between each parameter and the WeCom console is shown in the screenshots above):
|
||||
|
||||
```json
|
||||
{
|
||||
"channel_type": "wechatcom_app",
|
||||
"single_chat_prefix": [""],
|
||||
"wechatcom_corp_id": "YOUR_CORP_ID",
|
||||
"wechatcomapp_token": "YOUR_TOKEN",
|
||||
"wechatcomapp_secret": "YOUR_SECRET",
|
||||
@@ -48,12 +66,25 @@ Required resources:
|
||||
| `wechatcomapp_aes_key` | EncodingAESKey from API reception config |
|
||||
| `wechatcomapp_port` | Listen port, default 9898 |
|
||||
|
||||
After starting the program, return to WeCom Admin Console to save **Message Server Configuration**, and add the server IP to **Enterprise Trusted IPs**.
|
||||
After configuration, start the program. When the log shows `http://0.0.0.0:9898/`, the program is running successfully. You need to open this port externally (e.g., allow it in the cloud server security group).
|
||||
|
||||
After the program starts, return to the WeCom Admin Console to save the **Message Server Configuration**. After saving successfully, you also need to add the server IP to **Enterprise Trusted IPs**, otherwise messages cannot be sent or received:
|
||||
|
||||
<img src="https://cdn.link-ai.tech/doc/20260228103224.png" width="520"/>
|
||||
|
||||
<Warning>
|
||||
If configuration fails: 1. Ensure firewall and security group allow the port; 2. Verify all parameters are consistent; 3. Certified enterprises must configure a filed domain.
|
||||
If the URL configuration callback fails or the configuration is unsuccessful:
|
||||
1. Ensure the server firewall is disabled and the security group allows the listening port
|
||||
2. Carefully check that Token, Secret Key and other parameter configurations are consistent, and that the URL format is correct
|
||||
3. Certified WeCom accounts must configure a filed domain matching the entity
|
||||
</Warning>
|
||||
|
||||
## 4. Usage
|
||||
|
||||
Search for the app name in WeCom to start chatting. To allow external WeChat users, share the invite QR code from **My Enterprise → WeChat Plugin**.
|
||||
Search for the app name you just created in WeCom to start chatting directly. You can run multiple instances listening on different ports to create multiple WeCom apps:
|
||||
|
||||
<img src="https://cdn.link-ai.tech/doc/20260228103228.png" width="720"/>
|
||||
|
||||
To allow external personal WeChat users to use the app, go to **My Enterprise → WeChat Plugin**, share the invite QR code. After scanning and following, personal WeChat users can join and chat with the app:
|
||||
|
||||
<img src="https://cdn.link-ai.tech/doc/20260228103232.png" width="520"/>
|
||||
|
||||
@@ -42,9 +42,15 @@ The Agent workspace is located at `~/cow` by default and stores system prompts,
|
||||
├── memory/ # Long-term memory storage
|
||||
│ ├── core.md # Core memory
|
||||
│ └── daily/ # Daily memory
|
||||
├── skills/ # Custom skills
|
||||
│ ├── skill-1/
|
||||
│ └── skill-2/
|
||||
└── skills/ # Custom skills
|
||||
├── skill-1/
|
||||
└── skill-2/
|
||||
```
|
||||
|
||||
Secret keys are stored separately in `~/.cow` directory for security:
|
||||
|
||||
```
|
||||
~/.cow/
|
||||
└── .env # Secret keys for skills
|
||||
```
|
||||
|
||||
|
||||
@@ -8,8 +8,7 @@ The [LinkAI](https://link-ai.tech) platform lets you flexibly switch between Ope
|
||||
```json
|
||||
{
|
||||
"use_linkai": true,
|
||||
"linkai_api_key": "YOUR_API_KEY",
|
||||
"linkai_app_code": "YOUR_APP_CODE"
|
||||
"linkai_api_key": "YOUR_API_KEY"
|
||||
}
|
||||
```
|
||||
|
||||
@@ -17,7 +16,6 @@ The [LinkAI](https://link-ai.tech) platform lets you flexibly switch between Ope
|
||||
| --- | --- |
|
||||
| `use_linkai` | Set to `true` to enable LinkAI interface |
|
||||
| `linkai_api_key` | Create at [LinkAI Console](https://link-ai.tech/console/interface) |
|
||||
| `linkai_app_code` | Optional. Code of the LinkAI agent (app or workflow) |
|
||||
| `model` | Leave empty to use the agent's default model. Can be switched flexibly on the platform. All models in the [model list](https://link-ai.tech/console/models) are supported |
|
||||
|
||||
See the [API documentation](https://docs.link-ai.tech/platform/api) for more details.
|
||||
|
||||
@@ -5,6 +5,7 @@ description: CowAgent version history
|
||||
|
||||
| Version | Date | Description |
|
||||
| --- | --- | --- |
|
||||
| [2.0.2](/en/releases/v2.0.2) | 2026.02.27 | Web Console upgrade, multi-channel concurrency, session persistence |
|
||||
| [2.0.1](/en/releases/v2.0.1) | 2026.02.27 | Built-in Web Search tool, smart context management, multiple fixes |
|
||||
| [2.0.0](/en/releases/v2.0.0) | 2026.02.03 | Full upgrade to AI super assistant |
|
||||
| 1.7.6 | 2025.05.23 | Web Channel optimization, AgentMesh plugin |
|
||||
|
||||
98
docs/en/releases/v2.0.2.mdx
Normal file
98
docs/en/releases/v2.0.2.mdx
Normal file
@@ -0,0 +1,98 @@
|
||||
---
|
||||
title: v2.0.2
|
||||
description: CowAgent 2.0.2 - Web Console upgrade, multi-channel concurrency, session persistence
|
||||
---
|
||||
|
||||
**Release Date**: 2026.02.27 | [Full Changelog](https://github.com/zhayujie/chatgpt-on-wechat/compare/2.0.1...master)
|
||||
|
||||
## Highlights
|
||||
|
||||
### 🖥️ Web Console Upgrade
|
||||
|
||||
The Web Console has been fully upgraded with streaming conversation output, visual display of tool execution and reasoning processes, and online management of **models, skills, memory, channels, and Agent configuration**.
|
||||
|
||||
#### Chat Interface
|
||||
|
||||
Supports streaming output with real-time display of the Agent's reasoning process and tool calls, providing intuitive observation of the Agent's decision-making:
|
||||
|
||||
<img width="850" src="https://cdn.link-ai.tech/doc/20260227180120.png" />
|
||||
|
||||
#### Model Management
|
||||
|
||||
Manage model configurations online without manually editing config files:
|
||||
|
||||
<img width="850" src="https://cdn.link-ai.tech/doc/20260227173811.png" />
|
||||
|
||||
#### Skill Management
|
||||
|
||||
View and manage Agent skills (Skills) online:
|
||||
|
||||
<img width="850" src="https://cdn.link-ai.tech/doc/20260227173403.png" />
|
||||
|
||||
#### Memory Management
|
||||
|
||||
View and manage Agent memory online:
|
||||
|
||||
<img width="850" src="https://cdn.link-ai.tech/doc/20260227173349.png" />
|
||||
|
||||
#### Channel Management
|
||||
|
||||
Manage connected channels online with real-time connect/disconnect operations:
|
||||
|
||||
<img width="850" src="https://cdn.link-ai.tech/doc/20260227173331.png" />
|
||||
|
||||
#### Scheduled Tasks
|
||||
|
||||
View and manage scheduled tasks online, including one-time tasks, fixed intervals, and Cron expressions:
|
||||
|
||||
<img width="850" src="https://cdn.link-ai.tech/doc/20260227173704.png" />
|
||||
|
||||
#### Logs
|
||||
|
||||
View Agent runtime logs in real-time for monitoring and troubleshooting:
|
||||
|
||||
<img width="850" src="https://cdn.link-ai.tech/doc/20260227173514.png" />
|
||||
|
||||
Related commits: [f1a1413](https://github.com/zhayujie/chatgpt-on-wechat/commit/f1a1413), [c0702c8](https://github.com/zhayujie/chatgpt-on-wechat/commit/c0702c8), [394853c](https://github.com/zhayujie/chatgpt-on-wechat/commit/394853c), [1c71c4e](https://github.com/zhayujie/chatgpt-on-wechat/commit/1c71c4e), [5e3eccb](https://github.com/zhayujie/chatgpt-on-wechat/commit/5e3eccb), [e1dc037](https://github.com/zhayujie/chatgpt-on-wechat/commit/e1dc037), [5edbf4c](https://github.com/zhayujie/chatgpt-on-wechat/commit/5edbf4c), [7d258b5](https://github.com/zhayujie/chatgpt-on-wechat/commit/7d258b5)
|
||||
|
||||
### 🔀 Multi-Channel Concurrency
|
||||
|
||||
Multiple channels (e.g., Feishu, DingTalk, WeCom, Web) can now run simultaneously, each in an independent thread without interference.
|
||||
|
||||
Configuration: Set multiple channels in `config.json` via `channel_type` separated by commas, or connect/disconnect channels in real-time from the Web Console's channel management page.
|
||||
|
||||
```json
|
||||
{
|
||||
"channel_type": "web,feishu,dingtalk"
|
||||
}
|
||||
```
|
||||
|
||||
Related commits: [4694594](https://github.com/zhayujie/chatgpt-on-wechat/commit/4694594), [7cce224](https://github.com/zhayujie/chatgpt-on-wechat/commit/7cce224), [7d258b5](https://github.com/zhayujie/chatgpt-on-wechat/commit/7d258b5), [c9adddb](https://github.com/zhayujie/chatgpt-on-wechat/commit/c9adddb)
|
||||
|
||||
### 💾 Session Persistence
|
||||
|
||||
Session history is now persisted to a local SQLite database. Conversation context is automatically restored after service restarts. Historical conversations in the Web Console are also restored.
|
||||
|
||||
Related commits: [29bfbec](https://github.com/zhayujie/chatgpt-on-wechat/commit/29bfbec), [9917552](https://github.com/zhayujie/chatgpt-on-wechat/commit/9917552), [925d728](https://github.com/zhayujie/chatgpt-on-wechat/commit/925d728)
|
||||
|
||||
## New Models
|
||||
|
||||
- **Gemini 3.1 Pro Preview**: Added `gemini-3.1-pro-preview` model support ([52d7cad](https://github.com/zhayujie/chatgpt-on-wechat/commit/52d7cad))
|
||||
- **Claude 4.6 Sonnet**: Added `claude-4.6-sonnet` model support ([52d7cad](https://github.com/zhayujie/chatgpt-on-wechat/commit/52d7cad))
|
||||
- **Qwen3.5 Plus**: Added `qwen3.5-plus` model support ([e59a289](https://github.com/zhayujie/chatgpt-on-wechat/commit/e59a289))
|
||||
- **MiniMax M2.5**: Added `Minimax-M2.5` model support ([48db538](https://github.com/zhayujie/chatgpt-on-wechat/commit/48db538))
|
||||
- **GLM-5**: Added `glm-5` model support ([48db538](https://github.com/zhayujie/chatgpt-on-wechat/commit/48db538))
|
||||
- **Kimi K2.5**: Added `kimi-k2.5` model support ([48db538](https://github.com/zhayujie/chatgpt-on-wechat/commit/48db538))
|
||||
- **Doubao 2.0 Code**: Added `doubao-2.0-code` coding-specialized model ([ab28ee5](https://github.com/zhayujie/chatgpt-on-wechat/commit/ab28ee5))
|
||||
- **DashScope Models**: Added Alibaba Cloud DashScope model name support ([ce58f23](https://github.com/zhayujie/chatgpt-on-wechat/commit/ce58f23))
|
||||
|
||||
## Website & Documentation
|
||||
|
||||
- **Official Website**: [cowagent.ai](https://cowagent.ai/)
|
||||
- **Documentation**: [docs.cowagent.ai](https://docs.cowagent.ai/)
|
||||
|
||||
## Bug Fixes
|
||||
|
||||
- **Gemini DingTalk image recognition**: Fixed Gemini unable to process image markers in DingTalk channel ([05a3304](https://github.com/zhayujie/chatgpt-on-wechat/commit/05a3304)) ([#2670](https://github.com/zhayujie/chatgpt-on-wechat/pull/2670)) Thanks [@SgtPepper114](https://github.com/SgtPepper114)
|
||||
- **Startup script dependencies**: Fixed dependency installation issue in `run.sh` script ([b6fc9fa](https://github.com/zhayujie/chatgpt-on-wechat/commit/b6fc9fa))
|
||||
- **Bare except cleanup**: Replaced `bare except` with `except Exception` for better exception handling ([adca89b](https://github.com/zhayujie/chatgpt-on-wechat/commit/adca89b)) ([#2674](https://github.com/zhayujie/chatgpt-on-wechat/pull/2674)) Thanks [@haosenwang1018](https://github.com/haosenwang1018)
|
||||
@@ -3,8 +3,6 @@ title: Image Vision
|
||||
description: Recognize images using OpenAI vision models
|
||||
---
|
||||
|
||||
# openai-image-vision
|
||||
|
||||
Analyze image content using OpenAI's GPT-4 Vision API, understanding objects, text, colors, and other elements in images.
|
||||
|
||||
## Dependencies
|
||||
|
||||
@@ -3,8 +3,6 @@ title: LinkAI Agent
|
||||
description: Integrate LinkAI platform multi-agent skill
|
||||
---
|
||||
|
||||
# linkai-agent
|
||||
|
||||
Use agents from the [LinkAI](https://link-ai.tech/) platform as Skills for multi-agent decision-making. The Agent intelligently selects based on agent names and descriptions, calling the corresponding application or workflow via `app_code`.
|
||||
|
||||
## Dependencies
|
||||
|
||||
@@ -3,8 +3,6 @@ title: Skill Creator
|
||||
description: Create custom skills through conversation
|
||||
---
|
||||
|
||||
# skill-creator
|
||||
|
||||
Quickly create, install, or update skills through natural language conversation.
|
||||
|
||||
## Dependencies
|
||||
|
||||
@@ -3,8 +3,6 @@ title: Web Fetch
|
||||
description: Fetch web page text content
|
||||
---
|
||||
|
||||
# web-fetch
|
||||
|
||||
Use curl to fetch web pages and extract readable text content. A lightweight web access method without browser automation.
|
||||
|
||||
## Dependencies
|
||||
|
||||
@@ -3,8 +3,6 @@ title: bash - Terminal
|
||||
description: Execute system commands
|
||||
---
|
||||
|
||||
# bash
|
||||
|
||||
Execute Bash commands in the current working directory, returns stdout and stderr. API keys configured via `env_config` are automatically injected into the environment.
|
||||
|
||||
## Dependencies
|
||||
|
||||
@@ -3,8 +3,6 @@ title: browser - Browser
|
||||
description: Access and interact with web pages
|
||||
---
|
||||
|
||||
# browser
|
||||
|
||||
Use a browser to access and interact with web pages, supports JavaScript-rendered dynamic pages.
|
||||
|
||||
## Dependencies
|
||||
|
||||
@@ -3,8 +3,6 @@ title: edit - File Edit
|
||||
description: Edit files via precise text replacement
|
||||
---
|
||||
|
||||
# edit
|
||||
|
||||
Edit files via precise text replacement. If `oldText` is empty, appends to the end of the file.
|
||||
|
||||
## Dependencies
|
||||
|
||||
@@ -3,8 +3,6 @@ title: env_config - Environment
|
||||
description: Manage API keys and secrets
|
||||
---
|
||||
|
||||
# env_config
|
||||
|
||||
Manage environment variables (API keys and secrets) in the workspace `.env` file, with secure conversational updates. Built-in security protection and desensitization.
|
||||
|
||||
## Dependencies
|
||||
|
||||
@@ -3,8 +3,6 @@ title: ls - Directory List
|
||||
description: List directory contents
|
||||
---
|
||||
|
||||
# ls
|
||||
|
||||
List directory contents, sorted alphabetically, directories suffixed with `/`, includes hidden files.
|
||||
|
||||
## Dependencies
|
||||
|
||||
@@ -3,8 +3,6 @@ title: memory - Memory
|
||||
description: Search and read long-term memory
|
||||
---
|
||||
|
||||
# memory
|
||||
|
||||
The memory tool contains two sub-tools: `memory_search` (search memory) and `memory_get` (read memory files).
|
||||
|
||||
## Dependencies
|
||||
|
||||
@@ -3,8 +3,6 @@ title: read - File Read
|
||||
description: Read file content
|
||||
---
|
||||
|
||||
# read
|
||||
|
||||
Read file content. Supports text files, PDF files, images (returns metadata), and more.
|
||||
|
||||
## Dependencies
|
||||
|
||||
@@ -3,8 +3,6 @@ title: scheduler - Scheduler
|
||||
description: Create and manage scheduled tasks
|
||||
---
|
||||
|
||||
# scheduler
|
||||
|
||||
Create and manage dynamic scheduled tasks with flexible scheduling and execution modes.
|
||||
|
||||
## Dependencies
|
||||
|
||||
@@ -3,8 +3,6 @@ title: send - File Send
|
||||
description: Send files to user
|
||||
---
|
||||
|
||||
# send
|
||||
|
||||
Send files to the user (images, videos, audio, documents, etc.), used when the user explicitly requests to send/share a file.
|
||||
|
||||
## Dependencies
|
||||
|
||||
@@ -3,8 +3,6 @@ title: web_search - Web Search
|
||||
description: Search the internet for real-time information
|
||||
---
|
||||
|
||||
# web_search
|
||||
|
||||
Search the internet for real-time information, news, research, and more. Supports two search backends with automatic fallback.
|
||||
|
||||
## Dependencies
|
||||
|
||||
@@ -3,8 +3,6 @@ title: write - File Write
|
||||
description: Create or overwrite files
|
||||
---
|
||||
|
||||
# write
|
||||
|
||||
Write content to a file. Creates the file if it doesn't exist, overwrites if it does. Automatically creates parent directories.
|
||||
|
||||
## Dependencies
|
||||
|
||||
@@ -48,7 +48,7 @@ cp config-template.json config.json
|
||||
python3 app.py
|
||||
```
|
||||
|
||||
运行后默认启动 Web 服务,访问 `http://localhost:9899/chat` 开始对话。
|
||||
运行后默认启动 Web 控制台,访问 `http://localhost:9899` 开始对话和管理Agent。
|
||||
|
||||
**服务器后台运行:**
|
||||
|
||||
|
||||
@@ -22,7 +22,7 @@ bash <(curl -sS https://cdn.link-ai.tech/code/cow/run.sh)
|
||||
5. 引导配置 AI 模型和通信渠道
|
||||
6. 启动服务
|
||||
|
||||
运行后默认启动 Web 服务,访问 `http://localhost:9899/chat` 开始对话。
|
||||
运行后默认启动 Web 控制台,访问 `http://localhost:9899` 开始对话和管理Agent。
|
||||
|
||||
## 管理命令
|
||||
|
||||
|
||||
@@ -42,9 +42,15 @@ Agent 的工作空间默认位于 `~/cow` 目录,用于存储系统提示词
|
||||
├── memory/ # Long-term memory storage
|
||||
│ ├── core.md # Core memory
|
||||
│ └── daily/ # Daily memory
|
||||
├── skills/ # Custom skills
|
||||
│ ├── skill-1/
|
||||
│ └── skill-2/
|
||||
└── skills/ # Custom skills
|
||||
├── skill-1/
|
||||
└── skill-2/
|
||||
```
|
||||
|
||||
秘钥文件单独存储在 `~/.cow` 目录(出于安全考虑):
|
||||
|
||||
```
|
||||
~/.cow/
|
||||
└── .env # Secret keys for skills
|
||||
```
|
||||
|
||||
|
||||
@@ -3,8 +3,6 @@ title: 豆包 Doubao
|
||||
description: 豆包 (火山方舟) 模型配置
|
||||
---
|
||||
|
||||
# 豆包 (Doubao)
|
||||
|
||||
```json
|
||||
{
|
||||
"model": "doubao-seed-2-0-code-preview-260215",
|
||||
|
||||
@@ -3,8 +3,6 @@ title: 智谱 GLM
|
||||
description: 智谱AI GLM 模型配置
|
||||
---
|
||||
|
||||
# 智谱AI (GLM)
|
||||
|
||||
```json
|
||||
{
|
||||
"model": "glm-5",
|
||||
|
||||
@@ -3,8 +3,6 @@ title: Kimi
|
||||
description: Kimi (Moonshot) 模型配置
|
||||
---
|
||||
|
||||
# Kimi (Moonshot)
|
||||
|
||||
```json
|
||||
{
|
||||
"model": "kimi-k2.5",
|
||||
|
||||
@@ -8,8 +8,7 @@ description: 通过 LinkAI 平台统一接入多种模型
|
||||
```json
|
||||
{
|
||||
"use_linkai": true,
|
||||
"linkai_api_key": "YOUR_API_KEY",
|
||||
"linkai_app_code": "YOUR_APP_CODE"
|
||||
"linkai_api_key": "YOUR_API_KEY"
|
||||
}
|
||||
```
|
||||
|
||||
@@ -17,7 +16,6 @@ description: 通过 LinkAI 平台统一接入多种模型
|
||||
| --- | --- |
|
||||
| `use_linkai` | 设为 `true` 启用 LinkAI 接口 |
|
||||
| `linkai_api_key` | 在 [控制台](https://link-ai.tech/console/interface) 创建 |
|
||||
| `linkai_app_code` | LinkAI 智能体(应用或工作流)的 code,选填 |
|
||||
| `model` | 留空则使用智能体默认模型,可在平台中灵活切换,[模型列表](https://link-ai.tech/console/models) 中的全部模型均可使用 |
|
||||
|
||||
参考 [接口文档](https://docs.link-ai.tech/platform/api) 了解更多。
|
||||
|
||||
@@ -3,8 +3,6 @@ title: 通义千问 Qwen
|
||||
description: 通义千问模型配置
|
||||
---
|
||||
|
||||
# 通义千问 (Qwen)
|
||||
|
||||
```json
|
||||
{
|
||||
"model": "qwen3.5-plus",
|
||||
|
||||
@@ -13,43 +13,43 @@ description: CowAgent 2.0.2 - Web 控制台升级、多通道同时运行、会
|
||||
|
||||
支持流式输出,可实时展示 Agent 的思考过程(Reasoning)和工具调用过程(Tool Calls),更直观地观察 Agent 的决策过程:
|
||||
|
||||
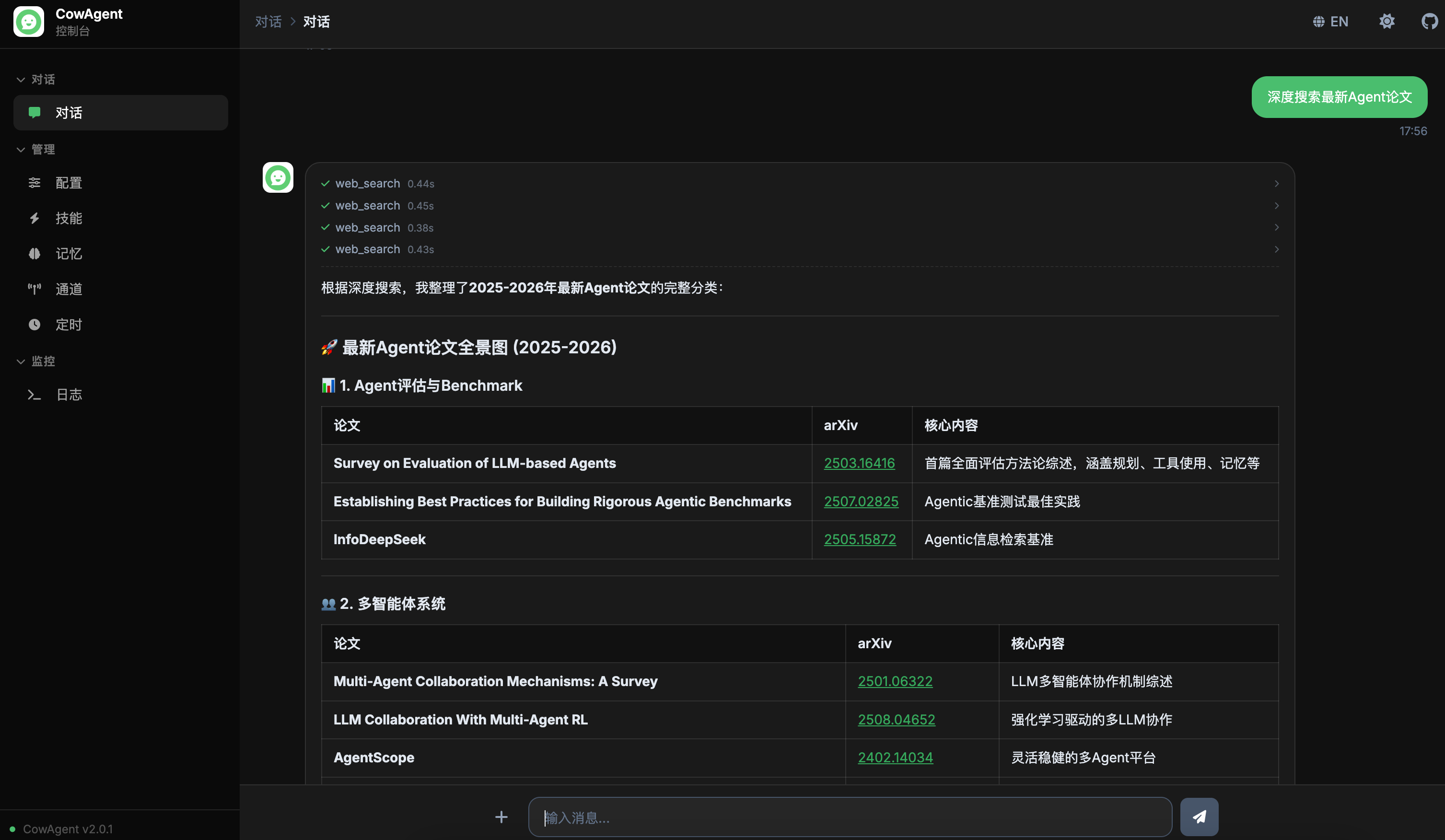
|
||||
<img width="850" src="https://cdn.link-ai.tech/doc/20260227180120.png" />
|
||||
|
||||
#### 模型管理
|
||||
|
||||
支持在线管理模型配置,无需手动编辑配置文件:
|
||||
|
||||
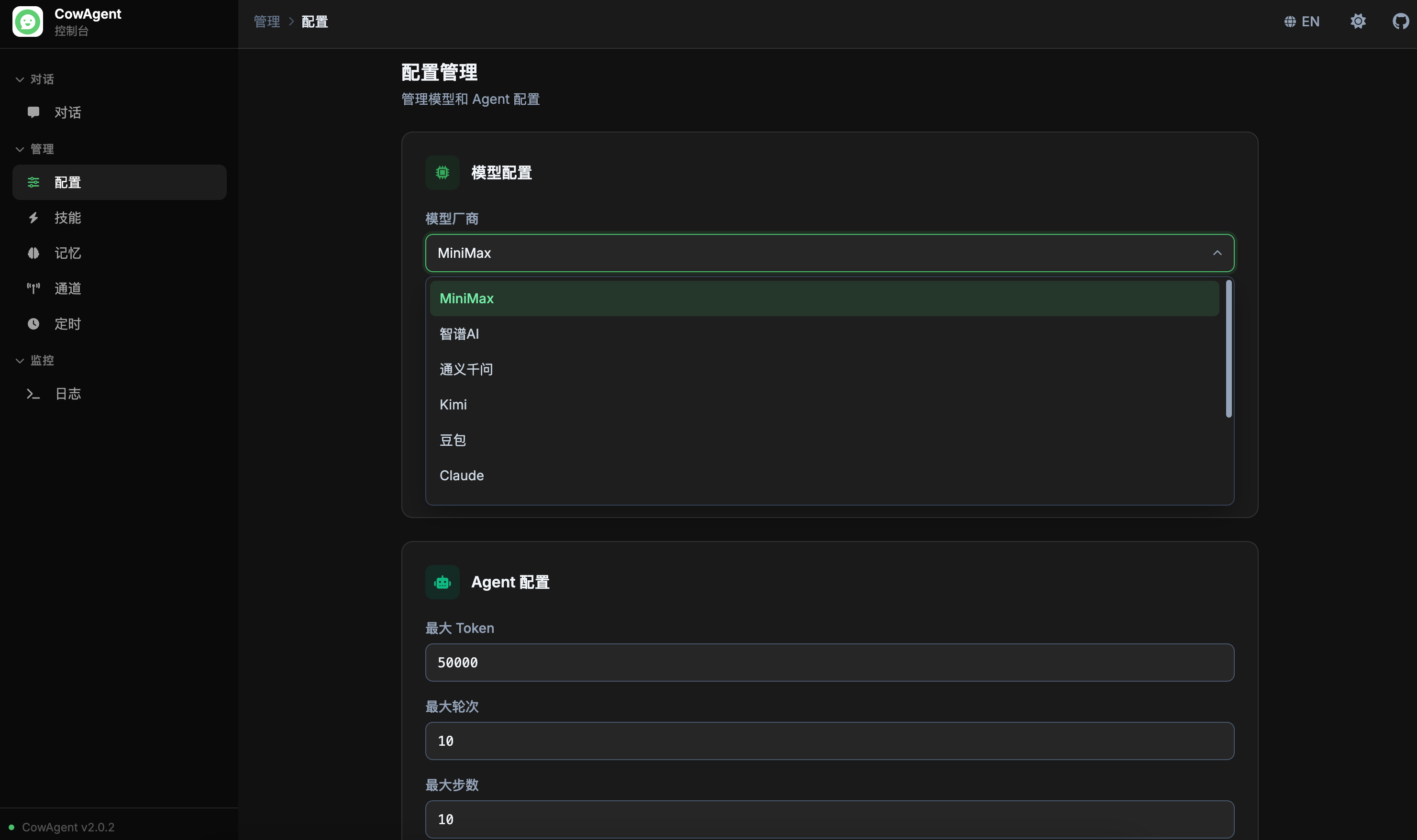
|
||||
<img width="850" src="https://cdn.link-ai.tech/doc/20260227173811.png" />
|
||||
|
||||
#### 技能管理
|
||||
|
||||
支持在线查看和管理 Agent 技能(Skills):
|
||||
|
||||
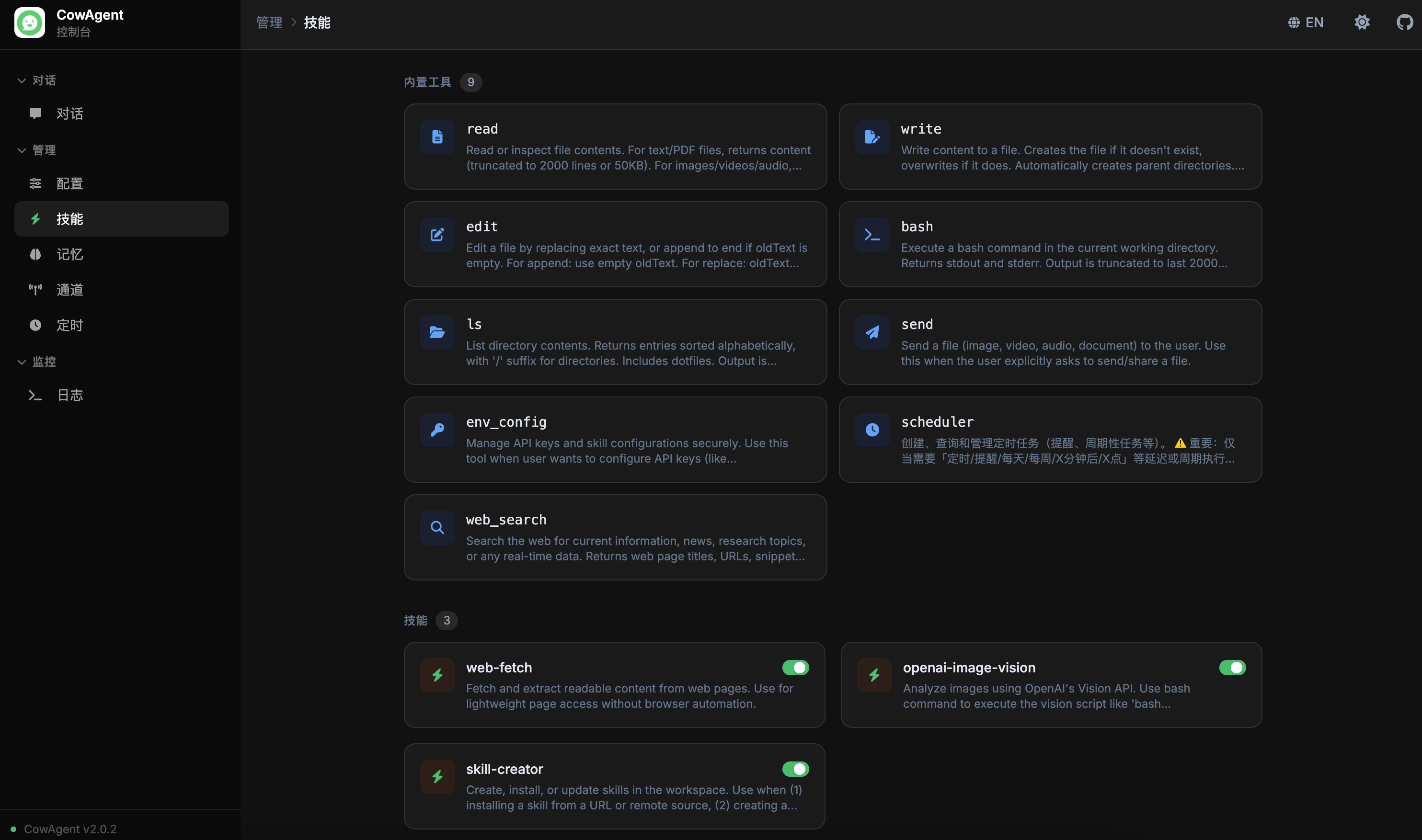
|
||||
<img width="850" src="https://cdn.link-ai.tech/doc/20260227173403.png" />
|
||||
|
||||
#### 记忆管理
|
||||
|
||||
支持在线查看和管理 Agent 记忆:
|
||||
|
||||
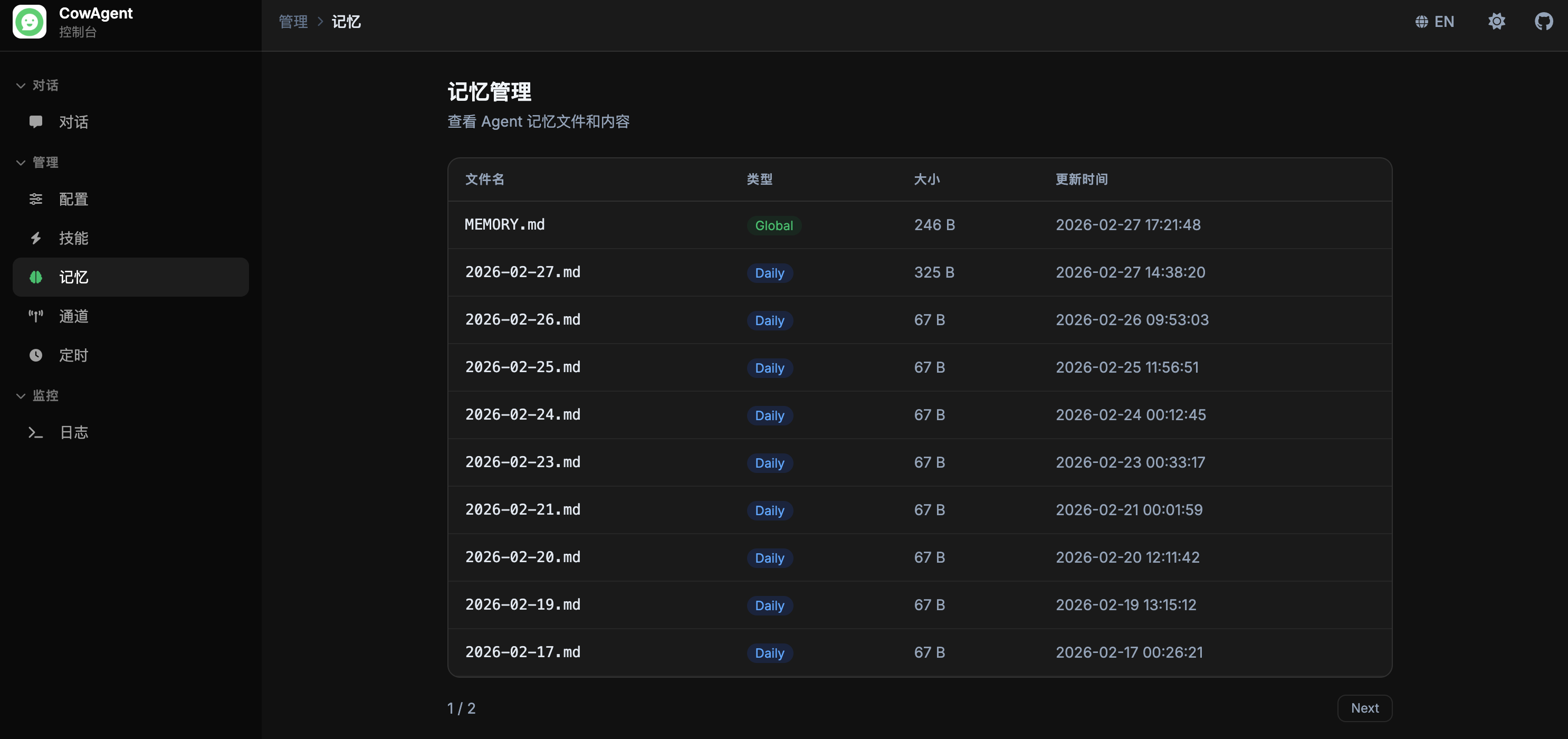
|
||||
<img width="850" src="https://cdn.link-ai.tech/doc/20260227173349.png" />
|
||||
|
||||
#### 通道管理
|
||||
|
||||
支持在线管理接入通道,支持实时连接/断开操作:
|
||||
|
||||
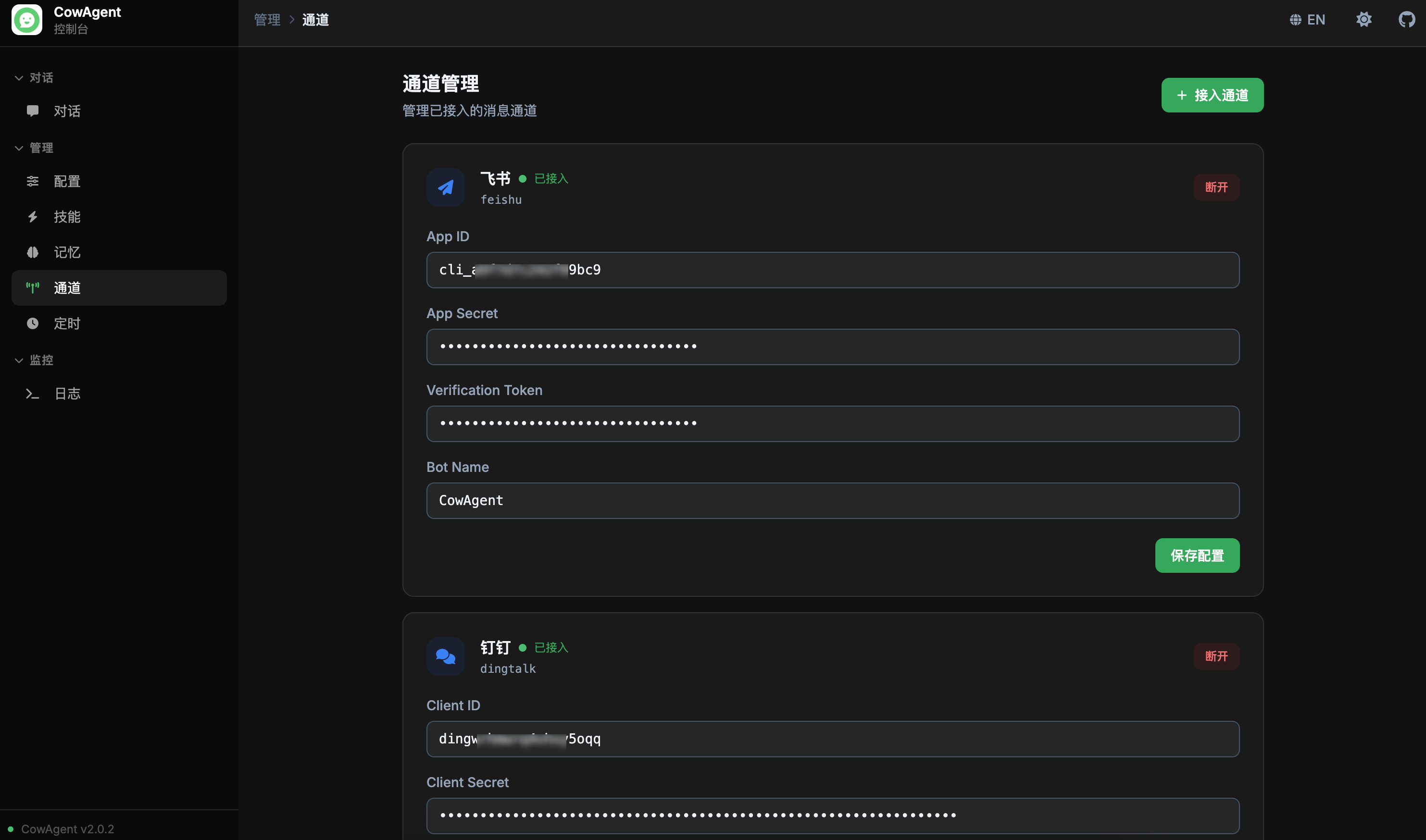
|
||||
<img width="850" src="https://cdn.link-ai.tech/doc/20260227173331.png" />
|
||||
|
||||
#### 定时任务
|
||||
|
||||
支持在线查看和管理定时任务,包括一次性任务、固定间隔、Cron 表达式等多种调度方式的可视化管理:
|
||||
|
||||
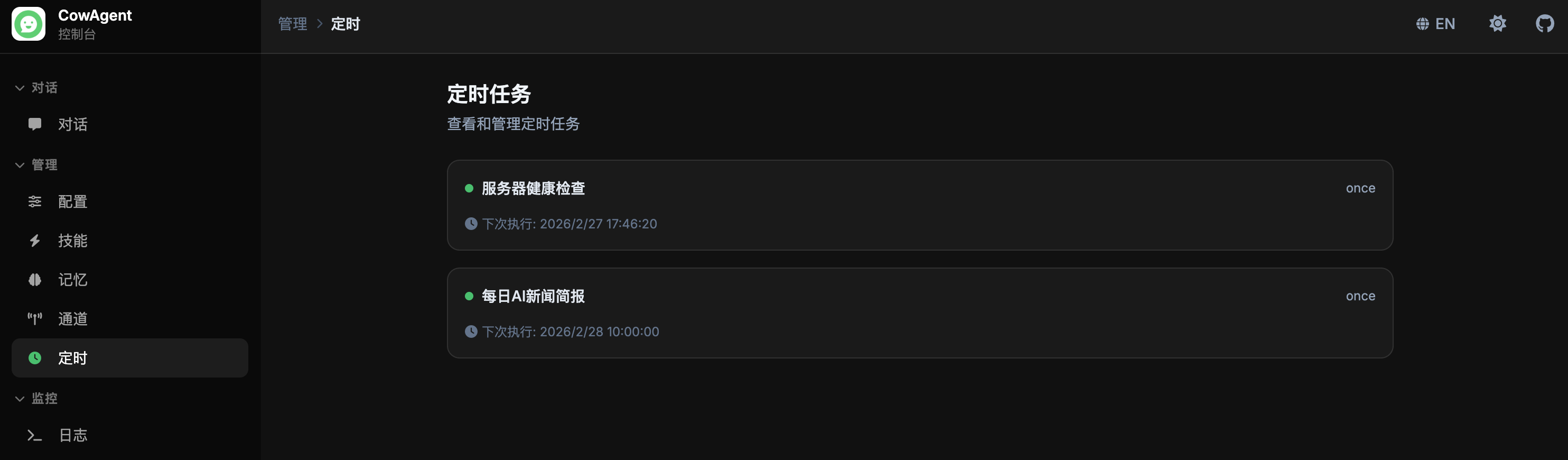
|
||||
<img width="850" src="https://cdn.link-ai.tech/doc/20260227173704.png" />
|
||||
|
||||
#### 日志
|
||||
|
||||
支持在线实时查看 Agent 运行日志,便于监控运行状态和排查问题:
|
||||
|
||||
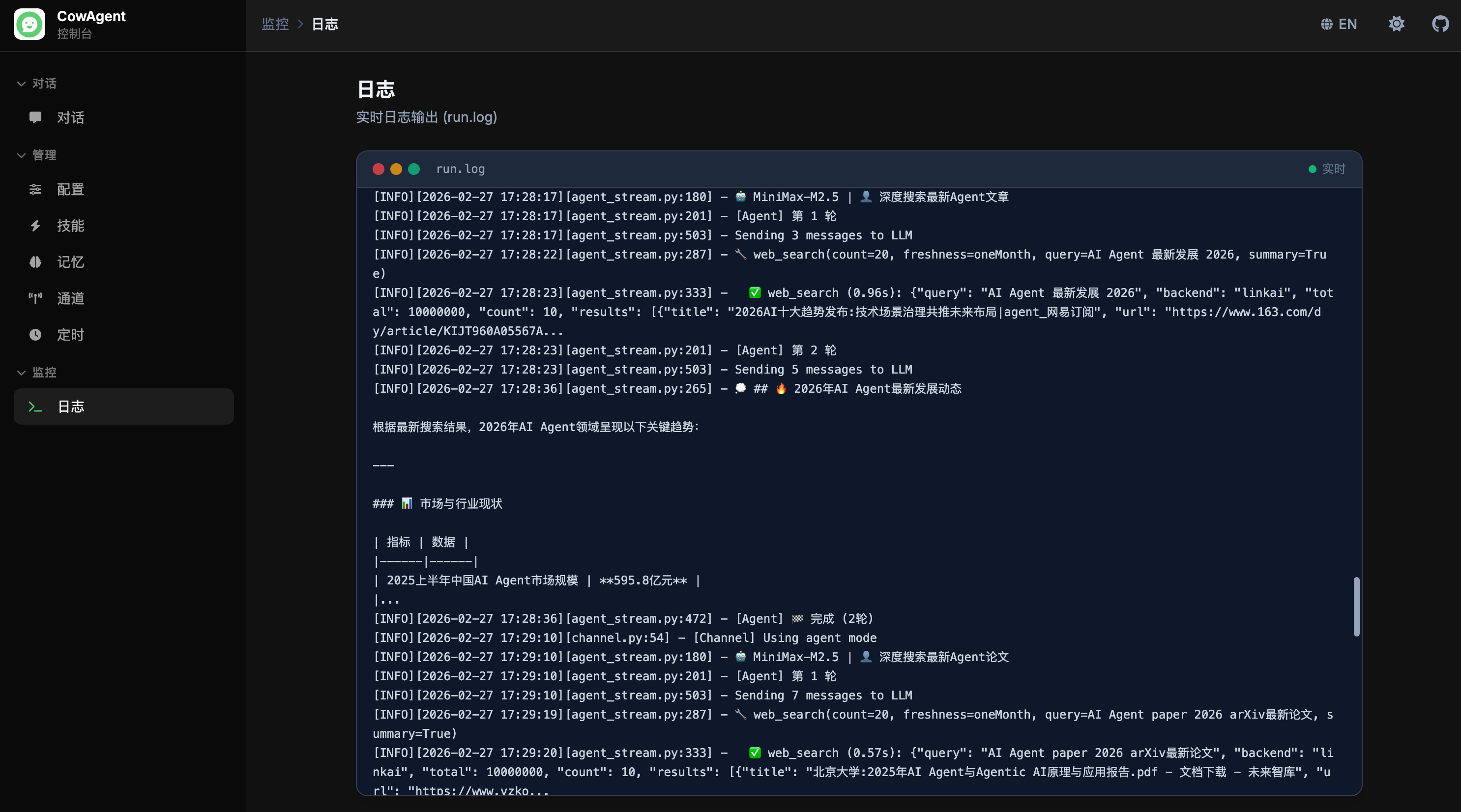
|
||||
<img width="850" src="https://cdn.link-ai.tech/doc/20260227173514.png" />
|
||||
|
||||
相关提交:[f1a1413](https://github.com/zhayujie/chatgpt-on-wechat/commit/f1a1413), [c0702c8](https://github.com/zhayujie/chatgpt-on-wechat/commit/c0702c8), [394853c](https://github.com/zhayujie/chatgpt-on-wechat/commit/394853c), [1c71c4e](https://github.com/zhayujie/chatgpt-on-wechat/commit/1c71c4e), [5e3eccb](https://github.com/zhayujie/chatgpt-on-wechat/commit/5e3eccb), [e1dc037](https://github.com/zhayujie/chatgpt-on-wechat/commit/e1dc037), [5edbf4c](https://github.com/zhayujie/chatgpt-on-wechat/commit/5edbf4c), [7d258b5](https://github.com/zhayujie/chatgpt-on-wechat/commit/7d258b5)
|
||||
|
||||
|
||||
@@ -3,8 +3,6 @@ title: 图像识别
|
||||
description: 使用 OpenAI 视觉模型识别图片
|
||||
---
|
||||
|
||||
# openai-image-vision
|
||||
|
||||
使用 OpenAI 的 GPT-4 Vision API 分析图片内容,理解图像中的物体、文字、颜色等元素。
|
||||
|
||||
## 依赖
|
||||
|
||||
@@ -3,8 +3,6 @@ title: LinkAI 智能体
|
||||
description: 对接 LinkAI 平台的多智能体技能
|
||||
---
|
||||
|
||||
# linkai-agent
|
||||
|
||||
将 [LinkAI](https://link-ai.tech/) 平台上的智能体作为 Skill 使用,实现多智能体决策。Agent 根据智能体的名称和描述智能选择,通过 `app_code` 调用对应的应用或工作流。
|
||||
|
||||
## 依赖
|
||||
|
||||
@@ -3,8 +3,6 @@ title: 创建技能
|
||||
description: 通过对话创建自定义技能
|
||||
---
|
||||
|
||||
# skill-creator
|
||||
|
||||
通过自然语言对话快速创建、安装或更新技能。
|
||||
|
||||
## 依赖
|
||||
|
||||
@@ -3,8 +3,6 @@ title: 网页抓取
|
||||
description: 抓取网页文本内容
|
||||
---
|
||||
|
||||
# web-fetch
|
||||
|
||||
使用 curl 抓取网页并提取可读文本内容,轻量级的网页访问方式,无需浏览器自动化。
|
||||
|
||||
## 依赖
|
||||
|
||||
@@ -3,8 +3,6 @@ title: bash - 终端
|
||||
description: 执行系统命令
|
||||
---
|
||||
|
||||
# bash
|
||||
|
||||
在当前工作目录执行 Bash 命令,返回 stdout 和 stderr。`env_config` 中配置的 API Key 会自动注入到环境变量中。
|
||||
|
||||
## 依赖
|
||||
|
||||
@@ -3,8 +3,6 @@ title: browser - 浏览器
|
||||
description: 访问和操作网页
|
||||
---
|
||||
|
||||
# browser
|
||||
|
||||
使用浏览器访问和操作网页,支持 JavaScript 渲染的动态页面。
|
||||
|
||||
## 依赖
|
||||
|
||||
@@ -3,8 +3,6 @@ title: edit - 文件编辑
|
||||
description: 通过精确文本替换编辑文件
|
||||
---
|
||||
|
||||
# edit
|
||||
|
||||
通过精确文本替换编辑文件。如果 `oldText` 为空则追加到文件末尾。
|
||||
|
||||
## 依赖
|
||||
|
||||
@@ -3,8 +3,6 @@ title: env_config - 环境变量
|
||||
description: 管理 API Key 等秘钥配置
|
||||
---
|
||||
|
||||
# env_config
|
||||
|
||||
管理工作空间 `.env` 文件中的环境变量(API Key 等秘钥),支持通过对话安全地添加和更新。内置安全保护和脱敏策略。
|
||||
|
||||
## 依赖
|
||||
|
||||
@@ -3,8 +3,6 @@ title: ls - 目录列表
|
||||
description: 列出目录内容
|
||||
---
|
||||
|
||||
# ls
|
||||
|
||||
列出目录内容,按字母排序,目录名带 `/` 后缀,包含隐藏文件。
|
||||
|
||||
## 依赖
|
||||
|
||||
@@ -3,8 +3,6 @@ title: memory - 记忆
|
||||
description: 搜索和读取长期记忆
|
||||
---
|
||||
|
||||
# memory
|
||||
|
||||
记忆工具包含两个子工具:`memory_search`(搜索记忆)和 `memory_get`(读取记忆文件)。
|
||||
|
||||
## 依赖
|
||||
|
||||
@@ -3,8 +3,6 @@ title: read - 文件读取
|
||||
description: 读取文件内容
|
||||
---
|
||||
|
||||
# read
|
||||
|
||||
读取文件内容。支持文本文件、PDF 文件、图片(返回元数据)等格式。
|
||||
|
||||
## 依赖
|
||||
|
||||
@@ -3,8 +3,6 @@ title: scheduler - 定时任务
|
||||
description: 创建和管理定时任务
|
||||
---
|
||||
|
||||
# scheduler
|
||||
|
||||
创建和管理动态定时任务,支持灵活的调度方式和执行模式。
|
||||
|
||||
## 依赖
|
||||
|
||||
@@ -3,8 +3,6 @@ title: send - 文件发送
|
||||
description: 向用户发送文件
|
||||
---
|
||||
|
||||
# send
|
||||
|
||||
向用户发送文件(图片、视频、音频、文档等),当用户明确要求发送/分享文件时使用。
|
||||
|
||||
## 依赖
|
||||
|
||||
@@ -3,8 +3,6 @@ title: web_search - 联网搜索
|
||||
description: 搜索互联网获取实时信息
|
||||
---
|
||||
|
||||
# web_search
|
||||
|
||||
搜索互联网获取实时信息、新闻、研究等内容。支持两个搜索后端,自动选择可用的后端。
|
||||
|
||||
## 依赖
|
||||
|
||||
@@ -3,8 +3,6 @@ title: write - 文件写入
|
||||
description: 创建或覆盖写入文件
|
||||
---
|
||||
|
||||
# write
|
||||
|
||||
写入内容到文件。文件不存在则自动创建,已存在则覆盖。自动创建父目录。
|
||||
|
||||
## 依赖
|
||||
|
||||
@@ -59,7 +59,7 @@ cp config.json.template config.json
|
||||
### 3. 调用应用
|
||||
|
||||
```bash
|
||||
bash scripts/call.sh "G7z6vKwp" "What is artificial intelligence?"
|
||||
bash(command='curl -sS --max-time 120 -X POST "https://api.link-ai.tech/v1/chat/completions" -H "Content-Type: application/json" -H "Authorization: Bearer $LINKAI_API_KEY" -d "{\"app_code\":\"G7z6vKwp\",\"messages\":[{\"role\":\"user\",\"content\":\"What is artificial intelligence?\"}],\"stream\":false}"', timeout=130)
|
||||
```
|
||||
|
||||
## 使用示例
|
||||
@@ -67,46 +67,32 @@ bash scripts/call.sh "G7z6vKwp" "What is artificial intelligence?"
|
||||
### 基础调用
|
||||
|
||||
```bash
|
||||
# 调用默认模型
|
||||
bash scripts/call.sh "G7z6vKwp" "解释一下量子计算"
|
||||
# 调用默认模型 (通过 bash + curl)
|
||||
bash(command='curl -sS --max-time 120 -X POST "https://api.link-ai.tech/v1/chat/completions" -H "Content-Type: application/json" -H "Authorization: Bearer $LINKAI_API_KEY" -d "{\"app_code\":\"G7z6vKwp\",\"messages\":[{\"role\":\"user\",\"content\":\"解释一下量子计算\"}],\"stream\":false}"', timeout=130)
|
||||
```
|
||||
|
||||
### 指定模型
|
||||
|
||||
```bash
|
||||
# 使用 GPT-4.1 模型
|
||||
bash scripts/call.sh "G7z6vKwp" "写一篇关于AI的文章" "LinkAI-4.1"
|
||||
在 JSON body 中添加 `model` 字段:
|
||||
|
||||
# 使用 DeepSeek 模型
|
||||
bash scripts/call.sh "G7z6vKwp" "帮我写代码" "deepseek-chat"
|
||||
|
||||
# 使用 Claude 模型
|
||||
bash scripts/call.sh "G7z6vKwp" "分析这段文本" "claude-4-sonnet"
|
||||
```json
|
||||
{
|
||||
"app_code": "G7z6vKwp",
|
||||
"model": "LinkAI-4.1",
|
||||
"messages": [{"role": "user", "content": "写一篇关于AI的文章"}],
|
||||
"stream": false
|
||||
}
|
||||
```
|
||||
|
||||
### 调用工作流
|
||||
|
||||
```bash
|
||||
# 工作流会按照配置的节点顺序执行
|
||||
bash scripts/call.sh "workflow_code" "输入数据或问题"
|
||||
```
|
||||
工作流的 app_code 从 LinkAI 控制台获取,调用方式与普通应用相同。
|
||||
|
||||
## ⚠️ 重要提示
|
||||
|
||||
### 超时配置
|
||||
|
||||
LinkAI 应用(特别是视频/图片生成、复杂工作流)可能需要较长时间处理。
|
||||
|
||||
**脚本内置超时**:
|
||||
- 默认:120 秒(适合大多数场景)
|
||||
- 可通过第 5 个参数自定义:`bash scripts/call.sh <app_code> <question> "" "false" "180"`
|
||||
|
||||
**推荐超时时间**:
|
||||
- **文本问答**:120 秒(默认)
|
||||
- **图片生成**:120-180 秒
|
||||
- **视频生成**:180-300 秒
|
||||
|
||||
Agent 调用时会自动设置合适的超时时间。
|
||||
LinkAI 应用(特别是视频/图片生成、复杂工作流)可能需要较长时间处理。在 curl 命令中加入 `--max-time 180`,并相应增加 bash 工具的 `timeout` 参数。
|
||||
|
||||
## 配置说明
|
||||
|
||||
@@ -125,38 +111,6 @@ Agent 调用时会自动设置合适的超时时间。
|
||||
3. 选择要集成的应用/工作流
|
||||
4. 在应用详情页找到 `app_code`
|
||||
|
||||
## 支持的模型
|
||||
|
||||
LinkAI 支持多种主流 AI 模型:
|
||||
|
||||
**OpenAI 系列:**
|
||||
- `LinkAI-4.1` - GPT-4.1 (1000K 上下文)
|
||||
- `LinkAI-4.1-mini` - GPT-4.1 mini (1000K)
|
||||
- `LinkAI-4.1-nano` - GPT-4.1 nano (1000K)
|
||||
- `LinkAI-4o` - GPT-4o (128K)
|
||||
- `LinkAI-4o-mini` - GPT-4o mini (128K)
|
||||
|
||||
**DeepSeek 系列:**
|
||||
- `deepseek-chat` - DeepSeek-V3 对话模型 (64K)
|
||||
- `deepseek-reasoner` - DeepSeek-R1 推理模型 (64K)
|
||||
|
||||
**Claude 系列:**
|
||||
- `claude-4-sonnet` - Claude 4 Sonnet (200K)
|
||||
- `claude-3-7-sonnet` - Claude 3.7 (200K)
|
||||
- `claude-3-5-sonnet` - Claude 3.5 (200K)
|
||||
|
||||
**Google 系列:**
|
||||
- `gemini-2.5-pro` - Gemini 2.5 Pro (1000K)
|
||||
- `gemini-2.0-flash` - Gemini 2.0 Flash (1000K)
|
||||
|
||||
**国产模型:**
|
||||
- `qwen3` - 通义千问3 (128K)
|
||||
- `wenxin-4.5` - 文心一言4.5 (8K)
|
||||
- `doubao-1.5-pro-256k` - 豆包1.5 (256K)
|
||||
- `glm-4-plus` - 智谱GLM-4-Plus (4K)
|
||||
|
||||
完整模型列表:https://link-ai.tech/console/models
|
||||
|
||||
## 应用类型
|
||||
|
||||
### 1. 普通应用
|
||||
@@ -185,10 +139,16 @@ LinkAI 支持多种主流 AI 模型:
|
||||
|
||||
### 成功响应
|
||||
|
||||
API 返回 OpenAI 兼容格式,从 `choices[0].message.content` 获取回复内容:
|
||||
|
||||
```json
|
||||
{
|
||||
"app_code": "G7z6vKwp",
|
||||
"content": "人工智能(AI)是计算机科学的一个分支...",
|
||||
"choices": [{
|
||||
"message": {
|
||||
"role": "assistant",
|
||||
"content": "人工智能(AI)是计算机科学的一个分支..."
|
||||
}
|
||||
}],
|
||||
"usage": {
|
||||
"prompt_tokens": 10,
|
||||
"completion_tokens": 150,
|
||||
@@ -201,9 +161,10 @@ LinkAI 支持多种主流 AI 模型:
|
||||
|
||||
```json
|
||||
{
|
||||
"error": "LinkAI API error",
|
||||
"message": "应用不存在",
|
||||
"response": { ... }
|
||||
"error": {
|
||||
"message": "应用不存在",
|
||||
"code": "xxx"
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
@@ -259,7 +220,7 @@ Agent 看到所有可用应用的完整信息
|
||||
↓
|
||||
Agent 根据描述选择合适的应用
|
||||
↓
|
||||
调用 call.sh <app_code> <question>
|
||||
通过 bash + curl 调用 LinkAI API
|
||||
↓
|
||||
LinkAI API 处理并返回结果
|
||||
```
|
||||
|
||||
@@ -1,6 +1,6 @@
|
||||
---
|
||||
name: linkai-agent
|
||||
description: Call LinkAI applications and workflows. Use bash command to execute like 'bash <base_dir>/scripts/call.sh <app_code> <question>'.
|
||||
description: Call LinkAI applications and workflows. Use bash with curl to invoke the chat completions API.
|
||||
homepage: https://link-ai.tech
|
||||
metadata:
|
||||
emoji: 🤖
|
||||
@@ -10,110 +10,61 @@ metadata:
|
||||
primaryEnv: "LINKAI_API_KEY"
|
||||
---
|
||||
|
||||
# LinkAI Agent Caller
|
||||
# LinkAI Agent
|
||||
|
||||
Call LinkAI applications and workflows through API. Supports multiple apps/workflows configured in config.json.
|
||||
|
||||
The available apps are dynamically loaded from `config.json` at skill loading time.
|
||||
Call LinkAI applications and workflows through the chat completions API. Available apps are loaded from config.json.
|
||||
|
||||
## Setup
|
||||
|
||||
This skill requires a LinkAI API key. If not configured:
|
||||
This skill requires a LinkAI API key.
|
||||
|
||||
1. Get your API key from https://link-ai.tech/console/api-keys
|
||||
2. Set the key using: `env_config(action="set", key="LINKAI_API_KEY", value="your-key")`
|
||||
1. Get your API key from [LinkAI Console](https://link-ai.tech/console/interface)
|
||||
2. Set the environment variable: `export LINKAI_API_KEY=Link_xxxxxxxxxxxx` (or use env_config tool)
|
||||
|
||||
## Configuration
|
||||
|
||||
1. Copy `config.json.template` to `config.json`
|
||||
2. Configure your apps/workflows:
|
||||
|
||||
```json
|
||||
{
|
||||
"apps": [
|
||||
{
|
||||
"app_code": "your_app_code",
|
||||
"app_name": "App Name",
|
||||
"app_description": "What this app does"
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
3. The skill description will be automatically updated when the agent loads this skill
|
||||
2. Add your apps/workflows in config.json. The skill description is auto-generated from this config when loaded.
|
||||
|
||||
## Usage
|
||||
|
||||
**Important**: Scripts are located relative to this skill's base directory.
|
||||
|
||||
When you see this skill in `<available_skills>`, note the `<base_dir>` path.
|
||||
|
||||
**CRITICAL**: Always use `bash` command to execute the script:
|
||||
Use the bash tool with curl to call the API. **Prefer curl** to avoid encoding issues on Windows PowerShell.
|
||||
|
||||
```bash
|
||||
# General pattern (MUST start with bash):
|
||||
bash "<base_dir>/scripts/call.sh" "<app_code>" "<question>" [model] [stream] [timeout]
|
||||
|
||||
# DO NOT execute the script directly like this (WRONG):
|
||||
# "<base_dir>/scripts/call.sh" ...
|
||||
|
||||
# Parameters:
|
||||
# - app_code: LinkAI app or workflow code (required)
|
||||
# - question: User question (required)
|
||||
# - model: Override model (optional, uses app default if not specified)
|
||||
# - stream: Enable streaming (true/false, default: false)
|
||||
# - timeout: curl timeout in seconds (default: 120, recommended for video/image generation)
|
||||
curl -X POST "https://api.link-ai.tech/v1/chat/completions" \
|
||||
-H "Content-Type: application/json" \
|
||||
-H "Authorization: Bearer $LINKAI_API_KEY" \
|
||||
-d '{
|
||||
"app_code": "<app_code>",
|
||||
"messages": [{"role": "user", "content": "<question>"}],
|
||||
"stream": false
|
||||
}'
|
||||
```
|
||||
|
||||
**IMPORTANT - Timeout Configuration**:
|
||||
- The script has a **default timeout of 120 seconds** (suitable for most cases)
|
||||
- For complex tasks (video generation, large workflows), pass a longer timeout as the 5th parameter
|
||||
- The bash tool also needs sufficient timeout - set its `timeout` parameter accordingly
|
||||
- Example: `bash(command="bash <script> <app_code> <question> '' 'false' 180", timeout=200)`
|
||||
**Optional parameters**:
|
||||
|
||||
## Examples
|
||||
- Add `--max-time 120` to curl for long-running tasks (video/image generation)
|
||||
|
||||
**On Windows cmd**: Use `%LINKAI_API_KEY%` instead of `$LINKAI_API_KEY`.
|
||||
|
||||
**Example** (via bash tool):
|
||||
|
||||
### Call an app (uses default 60s timeout)
|
||||
```bash
|
||||
bash(command='bash "<base_dir>/scripts/call.sh" "G7z6vKwp" "What is AI?"', timeout=60)
|
||||
bash(command='curl -sS --max-time 120 -X POST "https://api.link-ai.tech/v1/chat/completions" -H "Content-Type: application/json" -H "Authorization: Bearer $LINKAI_API_KEY" -d "{\"app_code\":\"G7z6vKwp\",\"messages\":[{\"role\":\"user\",\"content\":\"What is AI?\"}],\"stream\":false}"', timeout=130)
|
||||
```
|
||||
|
||||
### Call an app with specific model
|
||||
```bash
|
||||
bash(command='bash "<base_dir>/scripts/call.sh" "G7z6vKwp" "Explain machine learning" "LinkAI-4.1"', timeout=60)
|
||||
```
|
||||
## Response
|
||||
|
||||
### Call a workflow with custom timeout (video generation)
|
||||
```bash
|
||||
# Pass timeout as 5th parameter to script, and set bash timeout slightly longer
|
||||
bash(command='bash "<base_dir>/scripts/call.sh" "workflow_code" "Generate a sunset video" "" "false" "180"', timeout=180)
|
||||
```
|
||||
```bash
|
||||
bash "<base_dir>/scripts/call.sh" "workflow_code" "Analyze this data: ..."
|
||||
```
|
||||
Success (extract `choices[0].message.content` from JSON):
|
||||
|
||||
## Supported Models
|
||||
|
||||
You can specify any LinkAI supported model:
|
||||
- `LinkAI-4.1` - Latest GPT-4.1 model (1000K context)
|
||||
- `LinkAI-4.1-mini` - GPT-4.1 mini (1000K context)
|
||||
- `LinkAI-4o` - GPT-4o model (128K context)
|
||||
- `LinkAI-4o-mini` - GPT-4o mini (128K context)
|
||||
- `deepseek-chat` - DeepSeek-V3 (64K context)
|
||||
- `deepseek-reasoner` - DeepSeek-R1 reasoning model
|
||||
- `claude-4-sonnet` - Claude 4 Sonnet (200K context)
|
||||
- `gemini-2.5-pro` - Gemini 2.5 Pro (1000K context)
|
||||
- And many more...
|
||||
|
||||
Full model list: https://link-ai.tech/console/models
|
||||
|
||||
## Response Format
|
||||
|
||||
Success response:
|
||||
```json
|
||||
{
|
||||
"app_code": "G7z6vKwp",
|
||||
"content": "AI stands for Artificial Intelligence...",
|
||||
"choices": [{
|
||||
"message": {
|
||||
"role": "assistant",
|
||||
"content": "AI stands for Artificial Intelligence..."
|
||||
}
|
||||
}],
|
||||
"usage": {
|
||||
"prompt_tokens": 10,
|
||||
"completion_tokens": 50,
|
||||
@@ -122,44 +73,13 @@ Success response:
|
||||
}
|
||||
```
|
||||
|
||||
Error response:
|
||||
Error:
|
||||
|
||||
```json
|
||||
{
|
||||
"error": "Error description",
|
||||
"message": "Detailed error message"
|
||||
"error": {
|
||||
"message": "Error description",
|
||||
"code": "error_code"
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
## Features
|
||||
|
||||
- ✅ **Multiple Apps**: Configure and call multiple LinkAI apps/workflows
|
||||
- ✅ **Dynamic Loading**: Apps are loaded from config.json at runtime
|
||||
- ✅ **Model Override**: Optionally specify model per request
|
||||
- ✅ **Streaming Support**: Enable streaming output
|
||||
- ✅ **Knowledge Base**: Apps can use configured knowledge bases
|
||||
- ✅ **Plugins**: Apps can use enabled plugins (image recognition, web search, etc.)
|
||||
- ✅ **Workflows**: Execute complex multi-step workflows
|
||||
|
||||
## Notes
|
||||
|
||||
- Each app/workflow maintains its own configuration (prompt, model, temperature, etc.)
|
||||
- Apps can have knowledge bases attached for domain-specific Q&A
|
||||
- Workflows execute from start node to end node and return final output
|
||||
- Token usage and costs depend on the model used
|
||||
- See LinkAI documentation for pricing: https://link-ai.tech/console/funds
|
||||
- The skill description is automatically generated from config.json when loaded
|
||||
|
||||
## Troubleshooting
|
||||
|
||||
**"LINKAI_API_KEY environment variable is not set"**
|
||||
- Use env_config tool to set the API key
|
||||
|
||||
**"app_code is required"**
|
||||
- Make sure you're passing the app_code as the first parameter
|
||||
|
||||
**"应用不存在" (App not found)**
|
||||
- Check that the app_code is correct
|
||||
- Ensure you have access to the app
|
||||
|
||||
**"账号积分额度不足" (Insufficient credits)**
|
||||
- Top up your LinkAI account credits
|
||||
|
||||
@@ -1,138 +0,0 @@
|
||||
#!/usr/bin/env bash
|
||||
# LinkAI Agent Caller
|
||||
# API Docs: https://api.link-ai.tech/v1/chat/completions
|
||||
|
||||
set -euo pipefail
|
||||
|
||||
app_code="${1:-}"
|
||||
question="${2:-}"
|
||||
model="${3:-}"
|
||||
stream="${4:-false}"
|
||||
timeout="${5:-120}" # Default 120 seconds for video/image generation
|
||||
|
||||
if [ -z "$app_code" ]; then
|
||||
echo '{"error": "app_code is required", "usage": "bash call.sh <app_code> <question> [model] [stream] [timeout]"}'
|
||||
exit 1
|
||||
fi
|
||||
|
||||
if [ -z "$question" ]; then
|
||||
echo '{"error": "question is required", "usage": "bash call.sh <app_code> <question> [model] [stream] [timeout]"}'
|
||||
exit 1
|
||||
fi
|
||||
|
||||
if [ -z "${LINKAI_API_KEY:-}" ]; then
|
||||
echo '{"error": "LINKAI_API_KEY environment variable is not set", "help": "Use env_config to set LINKAI_API_KEY"}'
|
||||
exit 1
|
||||
fi
|
||||
|
||||
# API endpoint
|
||||
api_url="https://api.link-ai.tech/v1/chat/completions"
|
||||
|
||||
# Build JSON request body
|
||||
if [ -n "$model" ]; then
|
||||
request_body=$(cat <<EOF
|
||||
{
|
||||
"app_code": "$app_code",
|
||||
"model": "$model",
|
||||
"messages": [
|
||||
{
|
||||
"role": "user",
|
||||
"content": "$question"
|
||||
}
|
||||
],
|
||||
"stream": $stream
|
||||
}
|
||||
EOF
|
||||
)
|
||||
else
|
||||
request_body=$(cat <<EOF
|
||||
{
|
||||
"app_code": "$app_code",
|
||||
"messages": [
|
||||
{
|
||||
"role": "user",
|
||||
"content": "$question"
|
||||
}
|
||||
],
|
||||
"stream": $stream
|
||||
}
|
||||
EOF
|
||||
)
|
||||
fi
|
||||
|
||||
# Call LinkAI API
|
||||
response=$(curl -sS --max-time "$timeout" \
|
||||
-X POST \
|
||||
-H "Authorization: Bearer $LINKAI_API_KEY" \
|
||||
-H "Content-Type: application/json" \
|
||||
-d "$request_body" \
|
||||
"$api_url" 2>&1)
|
||||
|
||||
curl_exit_code=$?
|
||||
|
||||
if [ $curl_exit_code -ne 0 ]; then
|
||||
echo "{\"error\": \"Failed to call LinkAI API\", \"details\": \"$response\"}"
|
||||
exit 1
|
||||
fi
|
||||
|
||||
# Simple JSON validation
|
||||
if [[ ! "$response" =~ ^[[:space:]]*[\{\[] ]]; then
|
||||
echo "{\"error\": \"Invalid JSON response from API\", \"response\": \"$response\"}"
|
||||
exit 1
|
||||
fi
|
||||
|
||||
# Check for API error (top-level error only, not content_filter_result)
|
||||
if echo "$response" | grep -q '^[[:space:]]*{[[:space:]]*"error"[[:space:]]*:' || echo "$response" | grep -q '"error"[[:space:]]*:[[:space:]]*{[^}]*"code"[[:space:]]*:[[:space:]]*"[^"]*"[^}]*"message"'; then
|
||||
# Make sure it's not just content_filter_result inside choices
|
||||
if ! echo "$response" | grep -q '"choices"[[:space:]]*:[[:space:]]*\['; then
|
||||
# Extract error message
|
||||
error_msg=$(echo "$response" | grep -o '"message"[[:space:]]*:[[:space:]]*"[^"]*"' | sed 's/"message"[[:space:]]*:[[:space:]]*"\(.*\)"/\1/' | head -1)
|
||||
error_code=$(echo "$response" | grep -o '"code"[[:space:]]*:[[:space:]]*"[^"]*"' | sed 's/"code"[[:space:]]*:[[:space:]]*"\(.*\)"/\1/' | head -1)
|
||||
|
||||
if [ -z "$error_msg" ]; then
|
||||
error_msg="Unknown API error"
|
||||
fi
|
||||
|
||||
# Provide friendly error message for content filter
|
||||
if [ "$error_code" = "content_filter_error" ] || echo "$error_msg" | grep -qi "content.*filter"; then
|
||||
echo "{\"error\": \"内容安全审核\", \"message\": \"您的问题或应用返回的内容触发了LinkAI的安全审核机制,请换一种方式提问或检查应用配置\", \"details\": \"$error_msg\"}"
|
||||
else
|
||||
echo "{\"error\": \"LinkAI API error\", \"message\": \"$error_msg\", \"code\": \"$error_code\"}"
|
||||
fi
|
||||
exit 1
|
||||
fi
|
||||
fi
|
||||
|
||||
# For non-stream mode, extract and format the response
|
||||
if [ "$stream" = "false" ]; then
|
||||
# Extract content from response
|
||||
content=$(echo "$response" | grep -o '"content"[[:space:]]*:[[:space:]]*"[^"]*"' | sed 's/"content"[[:space:]]*:[[:space:]]*"\(.*\)"/\1/' | head -1)
|
||||
|
||||
# Extract usage information
|
||||
prompt_tokens=$(echo "$response" | grep -o '"prompt_tokens"[[:space:]]*:[[:space:]]*[0-9]*' | grep -o '[0-9]*' | head -1)
|
||||
completion_tokens=$(echo "$response" | grep -o '"completion_tokens"[[:space:]]*:[[:space:]]*[0-9]*' | grep -o '[0-9]*' | head -1)
|
||||
total_tokens=$(echo "$response" | grep -o '"total_tokens"[[:space:]]*:[[:space:]]*[0-9]*' | grep -o '[0-9]*' | head -1)
|
||||
|
||||
if [ -n "$content" ]; then
|
||||
# Unescape JSON content
|
||||
content=$(echo "$content" | sed 's/\\n/\n/g' | sed 's/\\"/"/g')
|
||||
|
||||
cat <<EOF
|
||||
{
|
||||
"app_code": "$app_code",
|
||||
"content": "$content",
|
||||
"usage": {
|
||||
"prompt_tokens": ${prompt_tokens:-0},
|
||||
"completion_tokens": ${completion_tokens:-0},
|
||||
"total_tokens": ${total_tokens:-0}
|
||||
}
|
||||
}
|
||||
EOF
|
||||
else
|
||||
# Return full response if we can't extract content
|
||||
echo "$response"
|
||||
fi
|
||||
else
|
||||
# For stream mode, return raw response (caller needs to handle streaming)
|
||||
echo "$response"
|
||||
fi
|
||||
Reference in New Issue
Block a user